张表专题
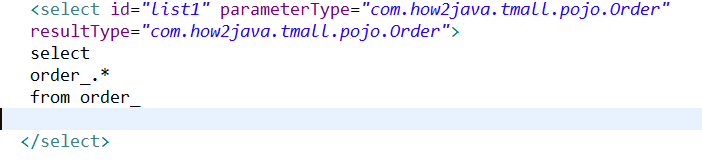

hive多张表join时,跑MR报错,org.apache.hadoop.hdfs.protocol.DSQuotaExceededException:The DiskSpace quota of /
hive多张表join报错! org.apache.hadoop.hdfs.protocol.DSQuotaExceededException:The DiskSpace quota of /目录 is exceeded:quota=9.7T but diskspace consumed = 9.7T at ........ 解决: 查看目录设置的配额情况,SPACE_QUOTA是
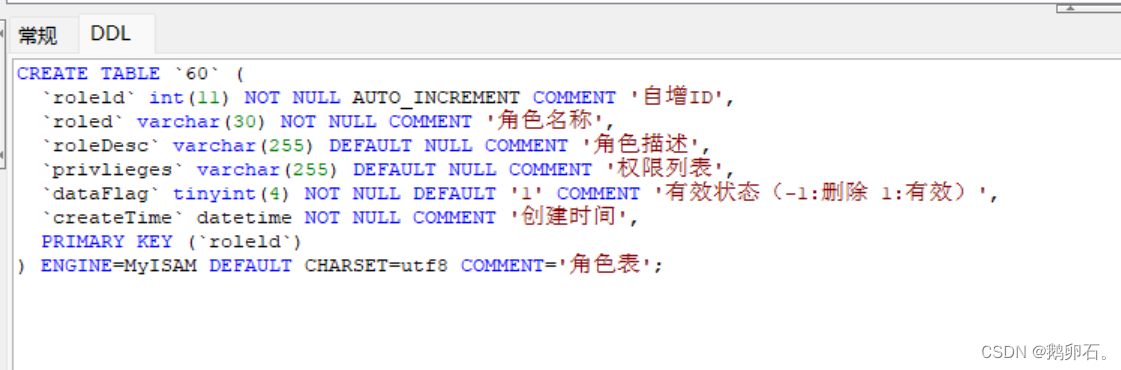
MySQL商城数据库88张表结构(71—75)
71、店铺运费模板表 CREATE TABLE `dingchengyu店铺运费模板表` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',`shopExpressId` int(11) NOT NULL COMMENT '快递ID',`tempName` varchar(100) NOT NULL COMMENT '模板名称',`temp

88张表-Mysql
店铺风格表-DDL CREATE TABLE `li_shop_styles` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',`styleSys` varchar(255) DEFAULT NULL COMMENT '风格适应的系统 例如电脑端 ,手机端微信端',`styleName` varchar(255) DEFAULT NULL

商城数据库88张表结构(二十)
DDL 77.店铺职员表 CREATE TABLE `wang_shop_users` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',`shopId` int(11) NOT NULL DEFAULT '0' COMMENT '店铺ID',`userId` int(11) NOT NULL DEFAULT '0' COMMENT '用
商城数据库88张表结构(十二)
DDL 45.商城信息表 CREATE TABLE `wang_messages` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',`msgType` tinyint(4) NOT NULL DEFAULT '0' COMMENT '消息类型(0:后台手工发送的消息 1:系统自动发的消息)',`sendUserid` int(11)
商城数据库88张表结构完整示意图
CREATE TABLE `orders` (`logId` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增ID',`orderId` int(11) NOT NULL DEFAULT '0' COMMENT '订单ID',`orderStatus` int(11) NOT NULL COMMENT '订单状态(和订单表对应)',`logContent` v
统计一个数据库内所有表的记录条数总和,统计一个数据库中有多少张表的SQL语句
--统计一个数据库内所有表的记录条数总和 select SUM(rowcounts) from (SELECT OBJECT_NAME(id) AS [TBName],MAX(rowcnt)[rowcounts] FROM sys.sysindexes GROUP BY OBJECT_NAME(id))ss --统计一个数据库中有多少张表的SQL语句 select
-自连接:通过表的别名,将同一张表视为多张表
--自连接:通过表的别名,将同一张表视为多张表 SQL> select e.ename||'的老板是'||b.ename 2 from emp e,emp b 3 where e.mgr=b.empno; E.ENAME||'的老板是'||B.ENAME
Oracle数据库中某张表的字段个数
Oracle中查询某个表的总字段数 select count(column_name) from user_tab_columns where table_name='T_B_AUDITOR' 通过大致查看: select tname,count(*) from col group by tname;

mysql经典4张表问题
1.数据库表结构关联图 2.问题: 1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数3.查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩4、查询名字中含有"风"字的学生信息5、查询课程名称为"数学",且分数低于60的学生姓名和分数6、查询所有学生的课程及分数情况;7、查询没学过"张三"老师授课的同学的信息8.查询学过"张三"老师授课的同学的信息9、查询学过编号为
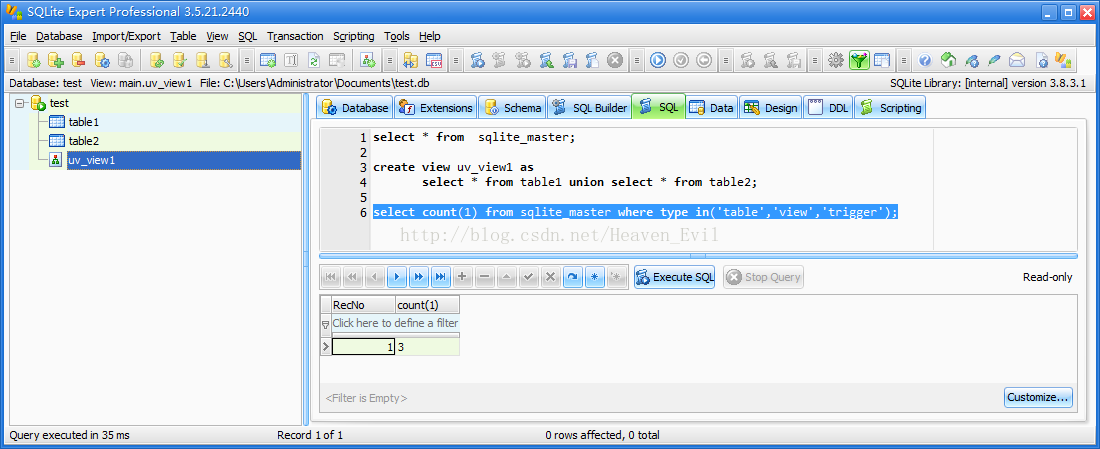
SQLite怎么统计一个数据库中有多少张表,视图或者触发器 .
sqlite数据库中表、视图和触发器的基本信息存储在一张叫做sqlite_master的系统表中,所以要想统计有多少张表就要先学习sqlite_master表。 每一个sqlite数据库都有一张叫做sqlite_master的表,它定义数据库的模式。sqlite_master的表结构如下: CREATE TABLE sqlite_master (type TEXT,name TE
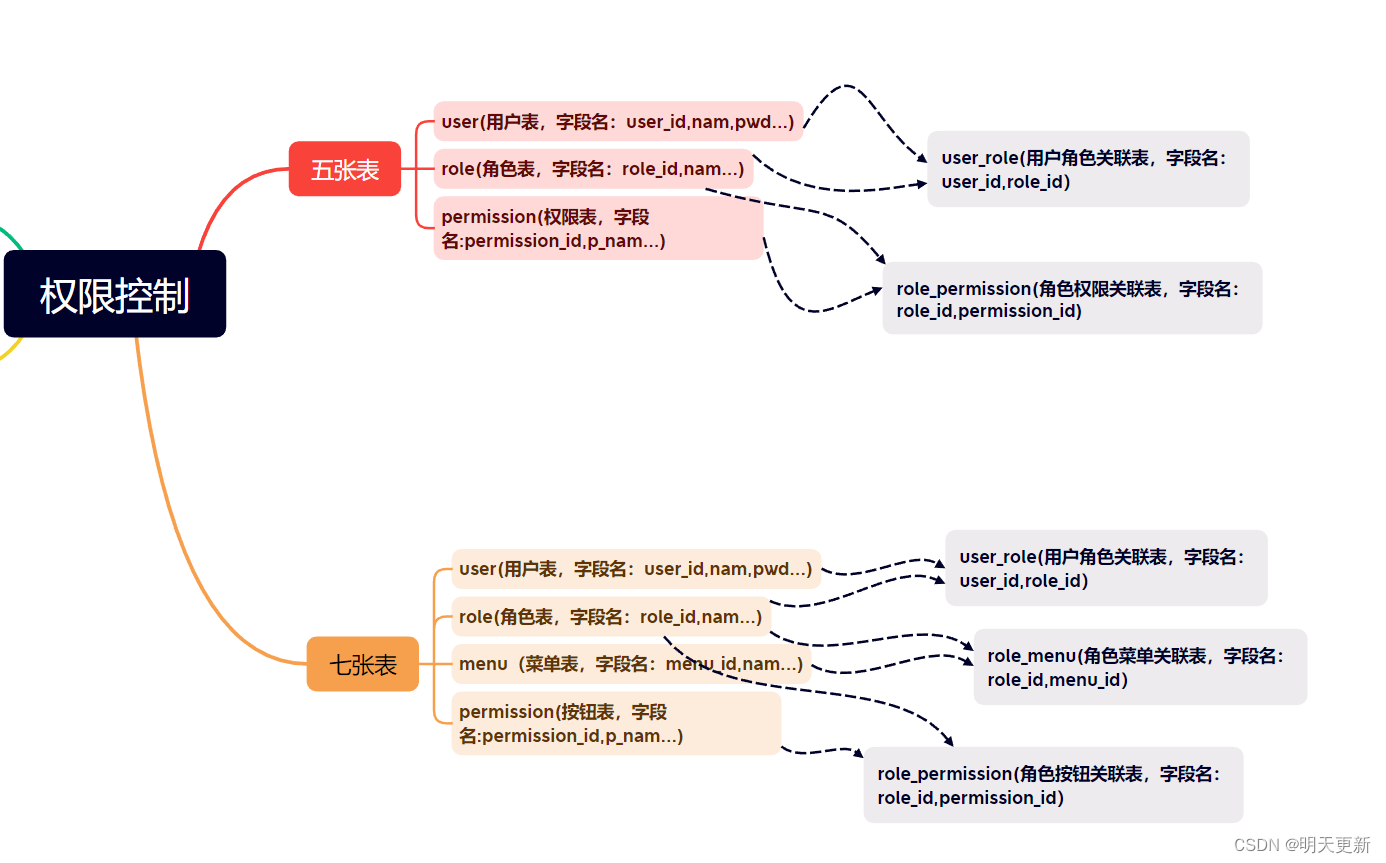
Spring Security关键之5张数据表与7张表 !!!
一、什么是认证和授权: 认证:系统提供的用于识别用户身份的功能,通常提供用户名和密码进行登录其实就是在进行认证,认证的目的是让系统知道你是谁。授权:用户认证成功后,需要为用户授权,其实就是指定当前用户可以操作哪些功能。 二:权限模块数据模型 --------------------Spring Security------------------------- 两个核心概念: 认证:登
SQLServer2005 判断数据库中是否存在某张表或是查找库中的所有表名,然后删除...
根据表名的个数判断:select count(name) as co from sysobjects where name = 'TD_RXNFDM' 查找苦中所有表的表名:SELECT [name] FROM sysobjects WHERE type='u' 删除某表:if exists (select name from sysobjects where name = '表名')drop
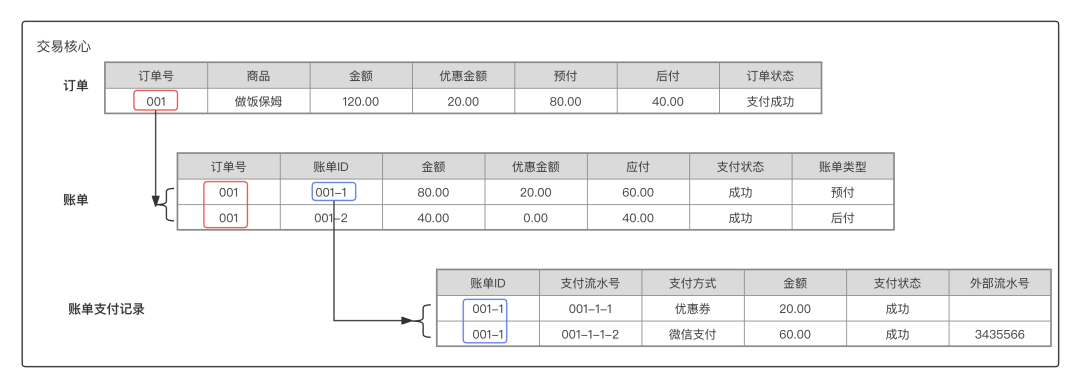
大厂交易系统从0到1(01)-一笔交易到底涉及多少张表?
退款逻辑,1个业务单号--关联多个支付单号--也关联多个退款单号?退款单号,关联优惠券返还的,也可在退款单列表关联吗?返还比例多少,是在优惠券系统设置? 整个交易、支付、清结算、账务体系杂糅,会产生很多单据、单号。再考虑正向、逆向,他们的关系更复杂。 本文就来搞定订单、账单、支付记录、支付单、支付请求、卡消费记录、券核销记录等单据,他们在交易正、逆向中是如何联系的,又有怎么样的数据关系。 0

【分享备忘录】Postgresql/pgsql 根据规则,批量联级删除多张表
来源:Chatgpt 测试调试:我 先上SQL语句如下: 联级删除单表 DROP TABLE IF EXISTS 表名 CASCADE 批量删除整张表 DO $$ DECLARE current_table_name text;BEGIN-- 获取所有以 'bgd_' 开头的表名FOR current_table_name IN SELECT table_name FROM i
如何在Spring Boot中使用@Scheduled写定时任务判断数据量是否过大,过大则进行分表操作,多张表使用临时视图查询
当数据量过大,在定时任务中执行分表操作 1、复制表结构及数据 在xml中编写复制表结构及数据(newTableName为新表名、originalTableName为原始表名) 只复制表结构: CREATE TABLE ${newTableName} AS SELECT * FROM ${originalTableName} WHERE 1=0; 复制表结构以及数据: CREAT
activity的25张表
ACT_RE_*: 'RE'表示repository。 这个前缀的表包含了流程定义和流程静态资源 (图片,规则,等等)。 ACT_RU_*: 'RU'表示runtime。 这些运行时的表,包含流程实例,任务,变量,异步任务,等运行中的数据。 Activiti只在流程实例执行过程中保存这些数据, 在流程结束时就会删除这些记录。 这样运行时表可以一直很小速度很快。 ACT_ID_*: 'ID'表示

会计从业备考:常用会计分录处理的8张表(附习题)
会计从业备考:常用会计分录处理的8张表(附习题) 一、资金筹集业务 二、固定资产业务 三、材料采购业务 四、生产业务 五、销售业务 六、期间费用 七、利润形成与分配 八、财产清查账务处理 下面来做做会计从业资格考试题库的精选习题: 【多选题】下列会计处理中,反映企业资金筹集业务的有()。 A、借记“银行存款”科目,贷记“实收资本”科目 B、借记“银行存款”科目,贷记“长期借款”科

通过sql语句快速查询数据库共有多少张表
一、无条件查询:select * from tab order by tname 二、过滤查询:select * from tab where tname not like '%$%' order by tname
Python合并一个 Excel 里面的多张表
刚需要将入职五个月的日报汇总, 但是每日都是在通一个excel里面新建副表写日报,现在已经积累了84张附表(每周4张,总共21周),手动复制粘贴每张表格是相当耗时的工作。在这个时候,我开始思考:有没有一种更快捷的方法来合并这些表格呢?于是,我想到了使用Python。 一、必要的库文件 Excel文件中包含多个工作表,并且想要将这些工作表合并成一个,可以使用Python的pandas库来处
【EasyExcel实践】万能导出,一个接口导出多张表以及任意字段(可指定字段顺序)
文章目录 前言正文一、POM依赖二、核心Java文件2.1 自定义表头注解 ExcelColumnTitle2.2 自定义标题头的映射接口2.3 自定义有序map存储表内数据2.4 表头工厂2.5 表flag和表头映射枚举2.6 测试用的实体2.6.1 NameAndFactoryDemo2.6.2 StudentDemo 2.7 启动类2.8 测试控制器 三、测试测试1测试2测试3测试4
【EasyExcel实践】万能导出,一个接口导出多张表以及任意字段(可指定字段顺序)
文章目录 前言正文一、POM依赖二、核心Java文件2.1 自定义表头注解 ExcelColumnTitle2.2 自定义标题头的映射接口2.3 自定义有序map存储表内数据2.4 表头工厂2.5 表flag和表头映射枚举2.6 测试用的实体2.6.1 NameAndFactoryDemo2.6.2 StudentDemo 2.7 启动类2.8 测试控制器 三、测试测试1测试2测试3测试4
postpresql 查询某张表的字段名和字段类型
postpresql 查询某张表的字段名和字段类型 工作中第一次接触postpresql,接触到这么个需求,只是对sql有点了解,于是就网上查阅资料。得知通过系统表可以查询,设计到几张系统表:pg_class、pg_attrubute、information_schema.columns 。 其中pg_class 这张表记录了所有表或者像表的东西。包括表、索引、视图、物化视图、组合类型和TOA