建表该专题

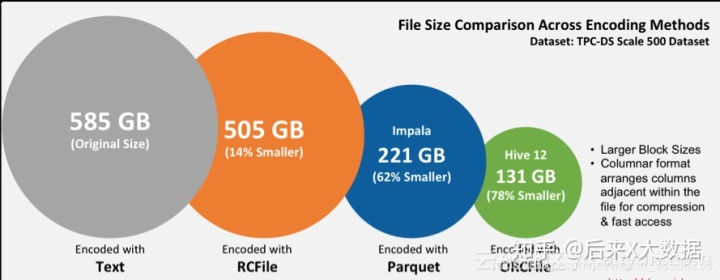
Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
因为上一篇文章中提到我在数仓的ods层因为使用的是 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'存储模式,但是遇到了count(*) 统计结果与select
hive 修改cluster by算法_Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
欢迎大家微信搜索:后来X大数据,更多精彩文章都会在公众号准时更新。 大家好,我是后来,周末理个发,赶脚人都精神了不少,哈哈。 因为上一篇文章中提到我在数仓的ods层因为使用的是 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.h