小菜专题

VC小菜之给软件添加背景音乐
1.新建DialogBase对话框工程项目PlayWave; 2.在CPlayWaveDlg.h 中添加 #include <Mmsystem.h> 3.添加链接库:在ProjectSetting(工程--设置) 对话框中选择Link(连接)选项卡,Category(类别)选择Input(输入), 在Object modules 输入 "Winmm.lib" 4.导入声音文件: 在资源

小菜读书--《大话设计模式》
小菜读书--《大话设计模式》 虽然有过三年的开发经历,但是还是小菜一枚,在大鸟的指导下,开始专业化进入软件这条道路。 首先大鸟推荐第一本书籍,就是《大话设计模式》。一边做笔记一边看书,书中以身边的故事,引出6种设计原则&23种设计模式。 历练使人成长,经验迸发灵感。然而所有的灵感都应有其因,那就是万变不离其宗的六大面向对象的设计原则,即单一职


ctfshow-Misc and Crypto WP(刚入门不久的小菜鸡一天两题左右持续更新ing)
目录 1.misc 2.misc2 3.miscx 4.misc50 5.misc30 6.stega1 7.misc3 8.misc40 9.misc30 10.红包第一弹 11.stega10 1.misc 伪加密题 拖入010,搜504b0102,修改其第五位09为00 解压即可 2.misc2 软盘题,写过一次又忘了 看别人的wp复

template设计模式 交通工具 java,小菜学习设计模式(一)—模板方法(Template)模式...
前言 设计模式目录: 本篇目录: 前段时间在亚马逊买了一本《CLR》的书,当时搞活动买一送一,然后挑了一本《漫谈设计模式》,一位不相识的大牛写的,这几天闲来无事,翻了几页瞧了瞧,感觉还是不错的,正好小菜也一直想学习设计模式,就决定认真的拜读下。 小菜写博文的目的是整理自己所整理的知识,小菜是一个喜欢收集的人,好的东西我都喜欢收藏起来,但是写出来就是另一回事了,一是锻炼自己的表达能力及回味所学的知

【Java】一只小菜坤的编程题之旅【4】
文章目录 1丶合并两个有序链表2丶栈的压入、弹出序列3丶设计循环队列4丶最小栈 1丶合并两个有序链表 小菜坤的答案: class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {ListNode newHead=new ListNode(0);ListNode tmp=ne

深入理解MapReduce:使用Java编写MapReduce程序【上进小菜猪】
📬📬我是上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。 MapReduce是一种用于处理大规模数据集的并行编程模型。由于其高效性和可扩展性,MapReduce已成为许多大型互联网公司处理大数据的首选方案。在本文中,我们将深入了解MapReduce,并使用Java编写一个简单的MapReduce程序。 MapReduce的原理 MapReduce由两个主要阶段组成:Map和R

HBase:Hadoop生态系统中的分布式NoSQL数据库【上进小菜猪大数据系列】
📬📬我是上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货,欢迎关注。 Hadoop中的HBase: 分布式NoSQL数据库 在大数据时代,数据量的爆炸式增长对数据存储和处理能力提出了巨大的挑战。Hadoop作为一个分布式计算框架,在解决这些挑战中发挥了重要作用。然而,传统的关系型数据库无法很好地处理海量的非结构化或半结构化数据,因此NoSQL数据库变得越来越受到关注和应用。在Had
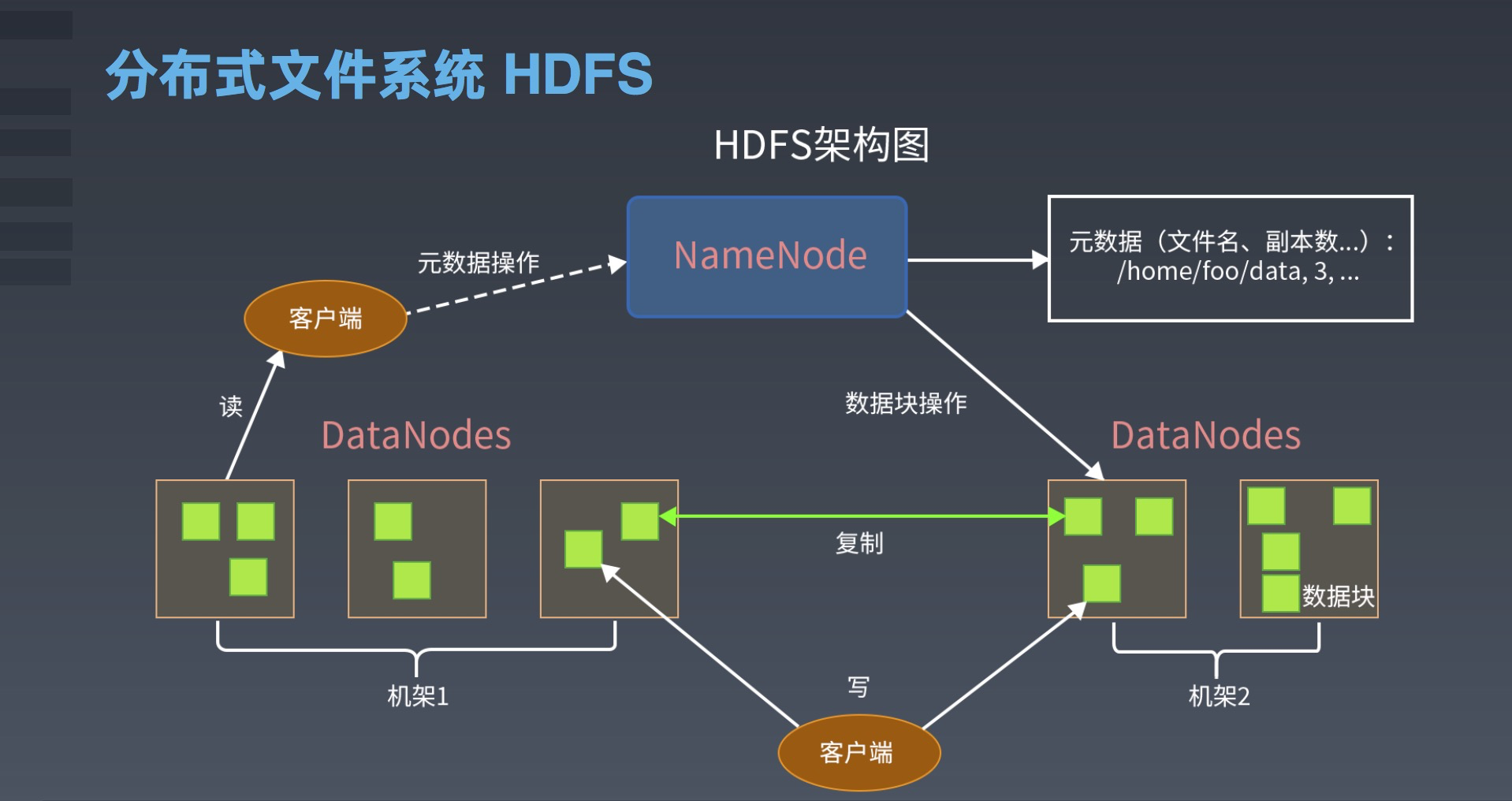
深入探究HDFS:高可靠、高可扩展、高吞吐量的分布式文件系统【上进小菜猪大数据系列】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。 引言 在当今数据时代,数据的存储和处理已经成为了各行各业的一个关键问题。尤其是在大数据领域,海量数据的存储和处理已经成为了一个不可避免的问题。为了应对这个问题,分布式文件系统应运而生。Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)就是其中一个开源的分布式文件系统。本文将介绍
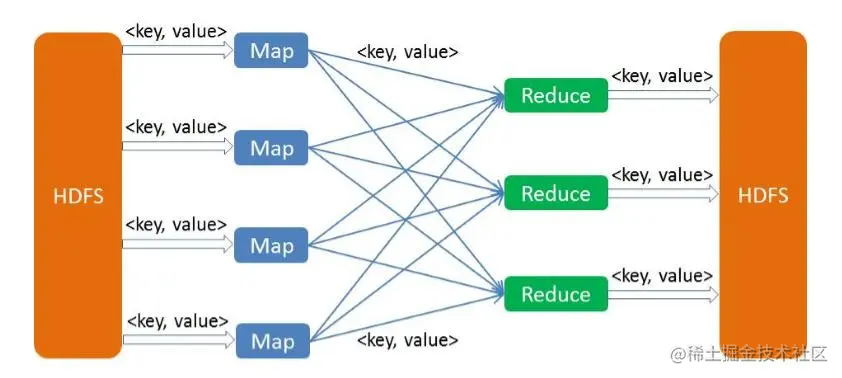
大数据处理领域的经典框架:MapReduce详解与应用【上进小菜猪大数据】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。 MapReduce是一个经典的大数据处理框架,可以帮助我们高效地处理庞大的数据集。本文将介绍MapReduce的基本原理和实现方法,并给出一个简单的示例。 一、MapReduce基本原理 MapReduce的基本原理包括两个阶段:Map和Reduce。 1、Map阶段 Map阶段的作用是将原始输入数据分解成一组键值对,以便后续的

大数据存储与处理技术探索:Hadoop HDFS与Amazon S3的无尽可能性【上进小菜猪大数据】
上进小菜猪,沈工大软件工程专业,爱好敲代码,持续输出干货。 大数据时代带来了数据规模的爆炸性增长,对于高效存储和处理海量数据的需求也日益迫切。本文将探索两种重要的大数据存储与处理技术:Hadoop HDFS和Amazon S3。我们将深入了解它们的特点、架构以及如何使用它们来构建可扩展的大数据解决方案。本文还将提供代码实例来说明如何使用这些技术来处理大规模数据集。 在当今数字化时代,大数据成为