子词专题

自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词
tokenization(二)子词切分方法
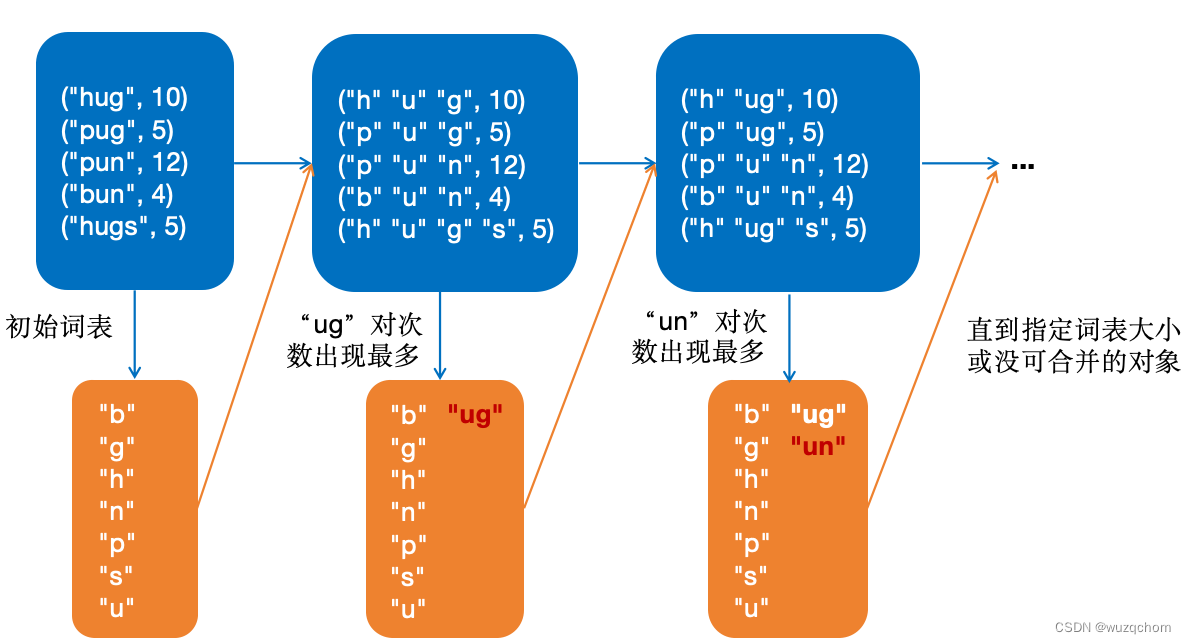
文章目录 概述BPE构建词表词元化代码实现 WordPieceUnigram估算概率(E)删除词元(M) 参考资料 概述 接上回,子词词元化(Subwords tokenization)是平衡字符级别和词级别的一种方法,也是目前用得最多的方法。 子词词元化的目标有2个: ● 常见词不应该切分为更小的单元 ● 罕见词应该被分解为有意义的子词 BPE BPE(Byte-Pair

NLP入门——数据预处理:子词切分及应用
BPE(Byte-Pair Encoding)算法 【西湖大学 张岳老师|自然语言处理在线课程 第十六章 - 4节】BPE(Byte-Pair Encoding)编码 如果有一个字符串aabaadaab,对其执行BPE算法 因为字符对aa出现频率最高,因此将其替换为码Z,这时原字符串变为ZbZdZb 此时字符对Zb出现频率最高,将其替换为码Y,此时原字符串变为YZdY 此时字符串中所有字符对