处理速度专题

利用Pandas的groupby和矢量化运算,减少显式循环,提高处理速度
目录 1. **`groupby` 机制****传统循环的缺点:****`groupby` 提高效率的方式:** 2. **矢量化运算****传统循环的缺点:****矢量化运算的优势:** 3. **结合`groupby`与矢量化运算**4. **对比示例****传统循环:****使用`groupby`和矢量化运算:** 5. **性能提升原因**6. **实际代码示例**结论

批处理JDBC语句以提高处理速度
批处理JDBC语句以提高处理速度 有的时候JDBC运行的不够理想,这就促使我们写一些与特定数据库相关的存储过程。作为一个替换方案,不妨试一下Statement的批处理特征,看看一次执行所有的SQL语句是否会带来速度的提升。存储过程最简单的形式就是整个过程只包含一组SQL语句。将这些语句放到一起能容易管理也可以提高运行速度。Statement类具有包含一串SQL语句的能力,因此它允许所有的SQL语

多线程是否能加快处理速度
问:多线程是不是能加快处理速度? 解析: 在使用多线程时,一定要知道一个道理:处理速度的最终决定因素是CPU、内存等,在单CPU(无论多少核)上,分配CPU资源的单位是“进程”而不是“线程”。 我们可以做一个简单的试验: 假设我要拷贝100万条数据,单CPU电脑,用一个进程,在单线程的情况下,CPU占用率为5%,耗时1000秒。那么当在这个进程下,开辟10个线程同时去运行,是不是CPU

python读取大型csv文件,降低内存占用,提高程序处理速度
文章目录 简介读取前多少行读取属性列逐块读取整个文件总结参考资料 简介 遇到大型的csv文件时,pandas会把该文件全部加载进内存,从而导致程序运行速度变慢。 本文提供了批量读取csv文件、读取属性列的方法,减轻内存占用情况。 import pandas as pdinput_file = 'data.csv' 读取前多少行 加载前100000行数据 df = pd
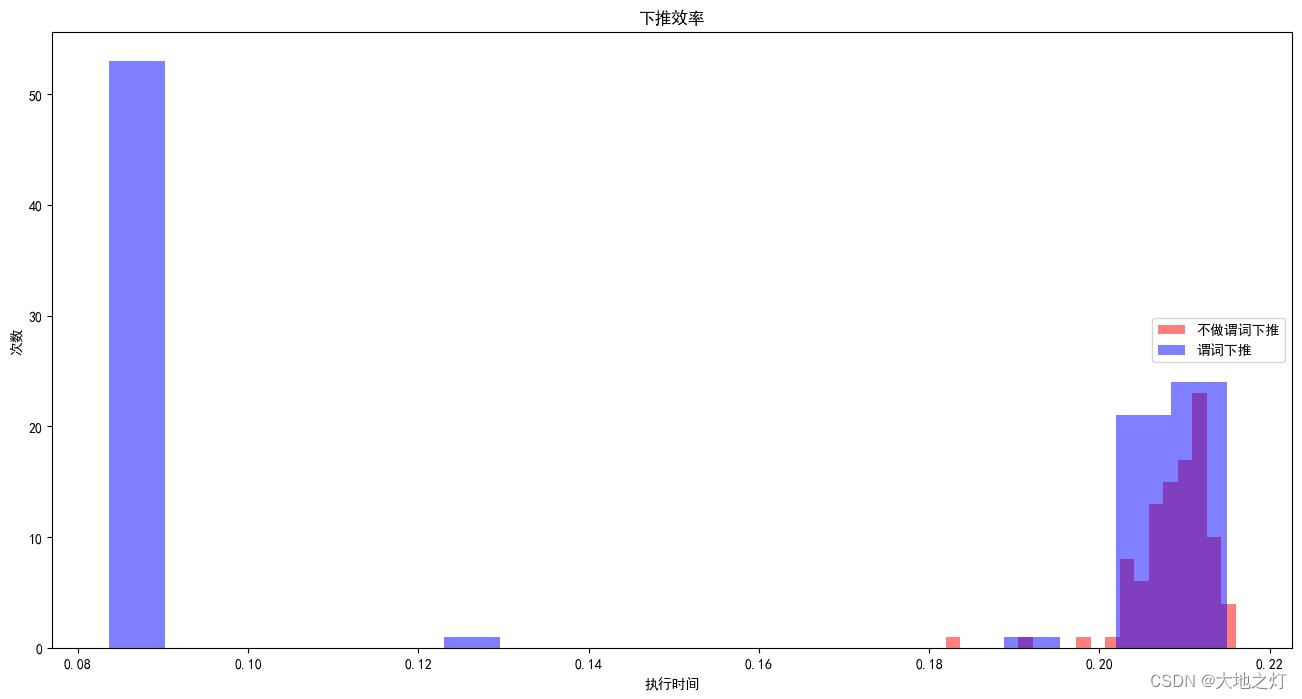
SQL进阶(三):Join 小技巧:提升数据的处理速度
复杂数据结构处理:Join 小技巧:提升数据的处理速度 本文是在原本sql闯关的基础上总结得来,加入了自己的理解以及疑问解答(by GPT4) 原活动链接 用到的数据:链接 提取码:l03e 目录 1. 课前小问答 🔎2. 开始之前的准备2. JOIN 基本语法2.1 关联方式 ( JOIN ) 的常见类型2.1.1. INNER JOIN (JOIN)2.1.2. LEFT JOI

比较 pandas 和 Polars 的处理速度和易用性
如果使用 Python,肯定会使用的库之一就是 pandas。 这是一个优秀的库,可以轻松处理表数据,其中一个后继者的库是 Polars。 尤其是在速度方面比pandas有优势,可以看作是能够解决pandas的弱点。 这次,想测量一下 pandas 和 Polars 之间的处理速度,并验证哪一个更好,包括易用性。 最后总结以下三点: 执行速度library的便利可以用polar取代panda

获取到异步函数的结果再执行后续代码_如何让 Python 处理速度翻倍?内含代码...
概念篇 在理解协程这个概念及其作用场景前,先要了解几个基本的关于操作系统的概念,主要是进程、线程、同步、异步、阻塞、非阻塞,了解这几个概念,不仅是对协程这个场景,诸如消息队列、缓存等,都有一定的帮助。接下来,编者就自己的理解和网上查询的材料,做一个总结。 进程 在面试的时候,我们都会记住一个概念,进程是系统资源分配的最小单位。是的,系统由一个个程序,也就是进程组成的,一般情况下,分为文本区域、数