入湖专题

Flink + Iceberg 如何解决数据入湖面临的挑战
本文来自4月17日 Apache Flink x Iceberg Meetup 上海站胡争老师的分享,文末有视频回顾和PPT资源下载~ 欢迎关注公众号,一起探讨交流! 【PPT下载】 https://files.alicdn.com/tpsservice/b201e20d578e1f3c7d
Fink CDC数据同步(六)数据入湖Hudi
数据入湖Hudi Apache Hudi(简称:Hudi)使得您能在hadoop兼容的存储之上存储大量数据,同时它还提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。这两种原语分别是: Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
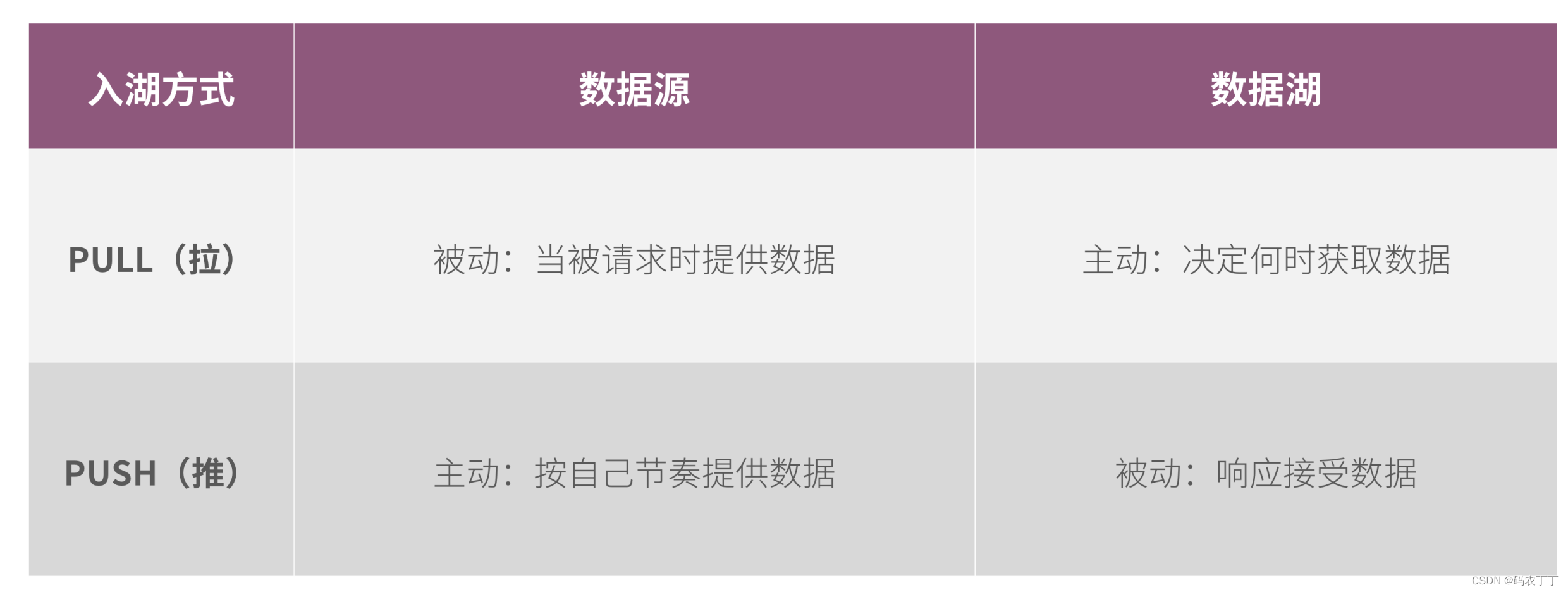
【华为数据之道学习笔记】5-4 数据入湖方式
数据入湖遵循华为信息架构,以逻辑数据实体为粒度入湖,逻辑数据实体在首次入湖时应该考虑信息的完整性。原则上,一个逻辑数据实体的所有属性应该一次性进湖,避免一个逻辑实体多次入湖,增加入湖工作量。 数据入湖的方式主要有物理入湖和虚拟入湖两种,根据数据消费的场景和需求,一个逻辑实体可以有不同的入湖方式。两种入湖方式相互协同,共同满足数据联接和用户数据消费的需求,数据管家有责任根据消费场景

基于Apache Hudi 的CDC数据入湖「内附干货PPT下载渠道」
一、CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Capture,即变更数据捕获,它是数据库领域非常常见的技术,主要用于捕获数据库的一些变更,然后可以把变更数据发送到下游。它的应用比较广,可以做一些数据同步、数据分发和数据采集,还可以做ETL,今天主要分享的也是把DB数据通过CDC的方式ETL到数据湖。 对于CDC,业界主要有两种类型:一是基于查询的,客户

数据仓库与数据湖的区别以及数据入湖方式
数据仓库与数据湖的区别 1)从使用对象来看,数据仓库主要是给 BI分析的数据分析师使用的,而数据湖是给AI处理的数据科学家使用,数据仓库也可以给AI使用,但是侧重点是 BI. 2)从数据处理的过程来看,数据仓库是ETL,抽取-清洗加载而数据湖是ELT,抽取-加载-清洗,即数据湖首先是直接讲数据存储,后续使用再进行清洗,而数据仓库在创建之初已经明确应用场景,所以先清洗再加载 3)从使用用途来看