人自专题
AdaVITS—基于VITS的小型化说话人自适应模型
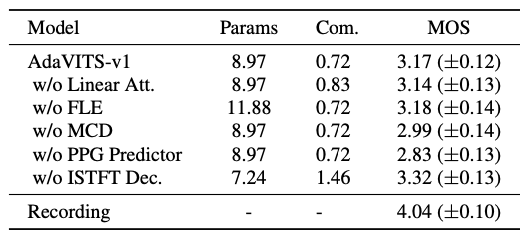
当前主流的实现小样本音色克隆的可靠方式是说话人自适应(speaker adaption)技术,该技术通常通过在预训练的多说话人文语转换 (TTS) 模型上使用少量的目标说话人数据进行微调而获得目标说话人的TTS模型。在这一任务上已经有很多相关工作,然而很多时候说话人自适应模型需要运行在手机等资源有限的设备上,需要轻量化的方案。 近期,由西工大音频语音与语言处理研究组 (ASLP@NPU) 和腾讯