亲和力专题
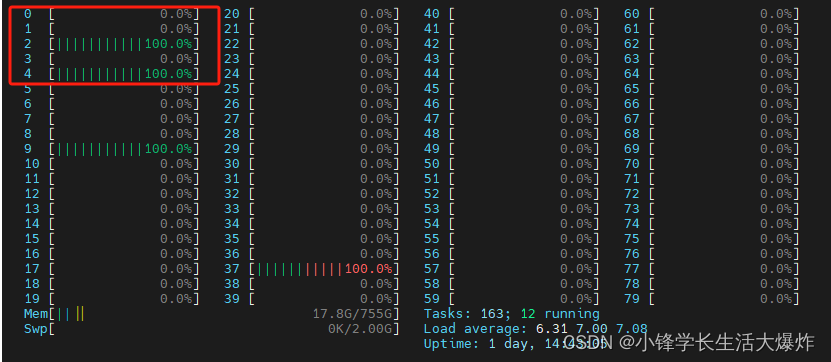
【教程】设置GPU与CPU的核绑(亲和力Affinity)
转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn] 如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~ 简单来说,核绑,或者叫亲和力,就是将某个GPU与指定CPU核心进行绑定,从而尽可能提高效率。 推荐与进程优先级一起用: 【教程】Linux设置进程的优先级-CSDN博客文章浏览阅读420次,点赞17次,收藏7次。对于时间敏感的任务调整进
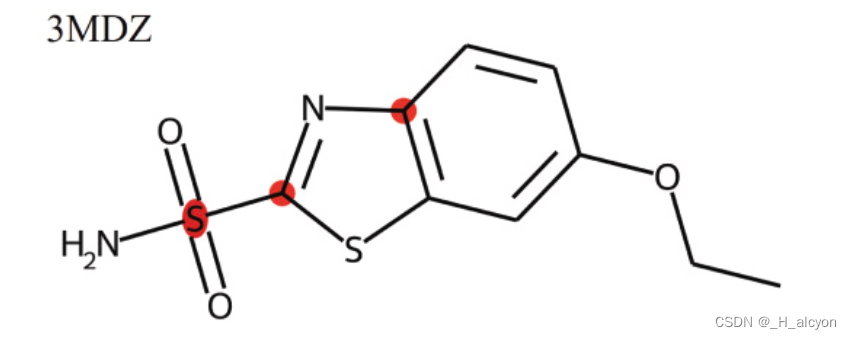
论文笔记ColdDTA:利用数据增强和基于注意力的特征融合进行药物靶标结合亲和力预测
ColdDTA发表在Computers in Biology and Medicine 的一篇一区文章 突出 • 数据增强和基于注意力的特征融合用于药物靶点结合亲和力预测。 • 与其他方法相比,它在 Davis、KIBA 和 BindingDB 数据集上显示出竞争性能。 • 可视化模型权重可以获得可解释的见解。 文章目录 ColdDTA发表在Computers in Biology
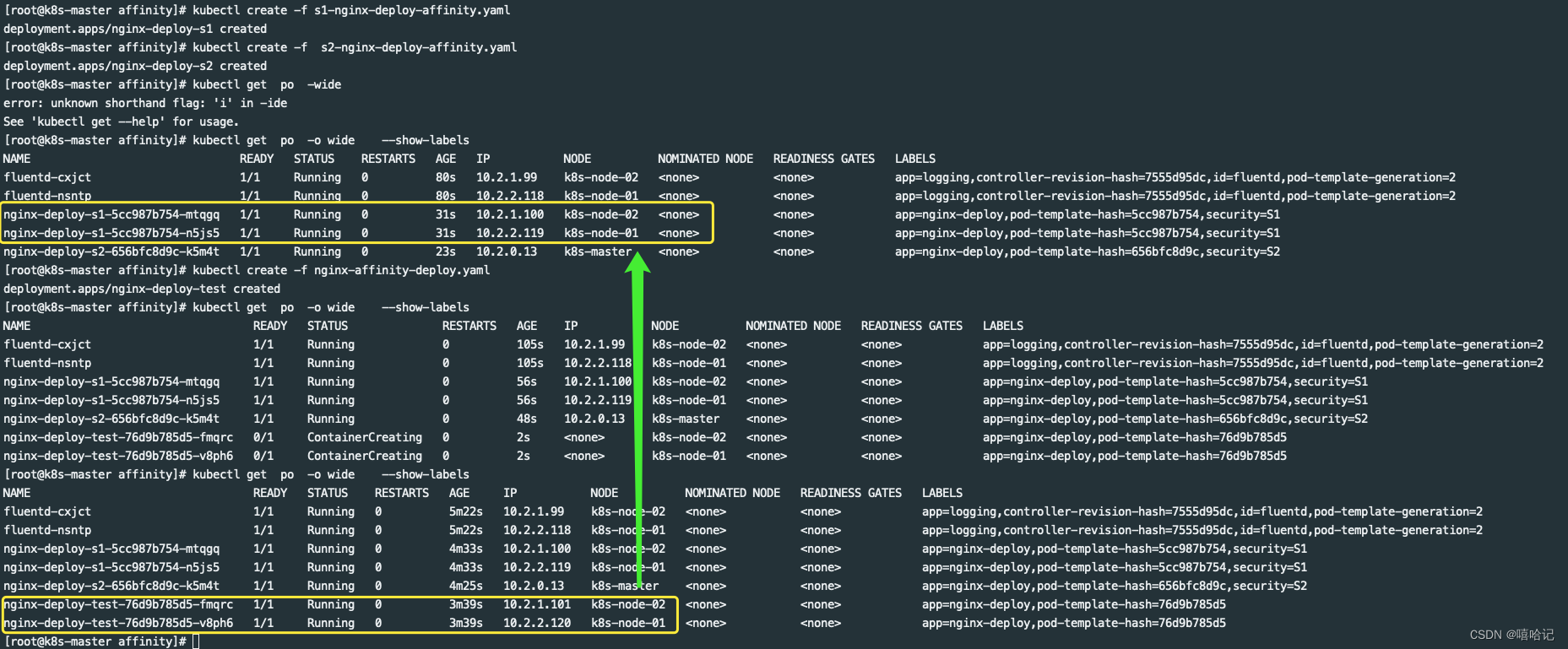
【k8s 高级调度--亲和力/反亲和力】
1、亲和性/反亲和性介绍 nodeSelector 提供了一种最简单的方法来将 Pod 约束到具有特定标签的节点上。 亲和性和反亲和性扩展了你可以定义的约束类型。使用亲和性与反亲和性的一些好处有: 亲和性、反亲和性语言的表达能力更强。nodeSelector 只能选择拥有所有指定标签的节点。 亲和性、反亲和性为你提供对选择逻辑的更强控制能力。你可以标明某规则是“软需求”或者“偏好”,这样调度器
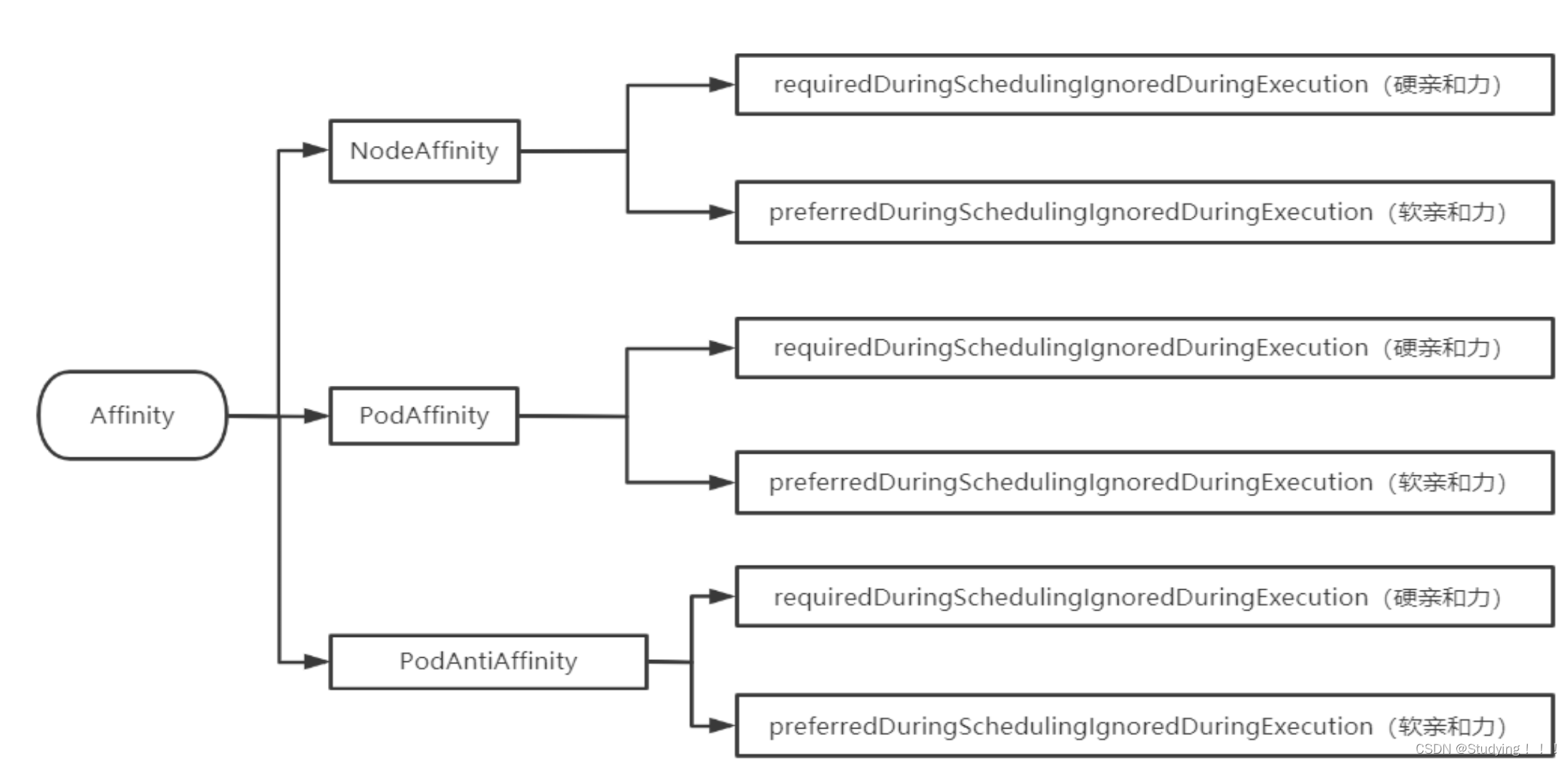
k8s-----24、亲和力Affinity
1、应用场景 pod和节点间的关系: 某些Pod优先选择有ssd=true标签的节点,如果没有在考虑部署到其它节点;某些Pod需要部署在ssd=true和type=physical的节点上,但是优先部署在ssd=true的节点上; pod和pod间的关系: 同一个应用的Pod不同的副本或者同一个项目的应用尽量或必须不部署在同一个节点或者符合某个标签的一类节点上或者不同的区域; #反亲和相
聚类笔记/sklearn笔记:Affinity Propagation亲和力传播
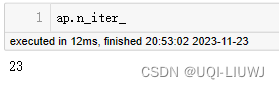
1 算法原理 1.1 基本思想 将全部数据点都当作潜在的聚类中心(称之为 exemplar )然后数据点两两之间连线构成一个网络( 相似度矩阵 )再通过网络中各条边的消息( responsibility 和 availability )传递计算出各样本的聚类中心。 1.2 主要概念 Examplar聚类中心similarity S(i,j) 相似度 一般使用负的欧式距离,所以 S(i

Python机器学习零基础理解AffinityPropagation亲和力传播聚类
如何解决社交媒体上的好友推荐问题? 想象一下,一个社交媒体平台希望提供更加精准的好友推荐功能,让用户能更容易地找到可能成为好友的人。这个问题看似简单,但当面对数百万甚至数千万的用户时,手动进行好友推荐就变得几乎不可能。 解决这个问题的一个方案就是使用机器学习算法进行自动推荐。更具体地说,可以使用一种名为"亲和力传播"(Affinity Propagation)的算法。这种算法能自动地将用户分为

学术速运|MFR-DTA:一个预测药物-靶点结合亲和力和区域的多功能模型
题目:MFR-DTA: A Multi-Functional and Robust Model for Predicting Drug-Target Binding Affinity and Region 文献来源: DOI: 10.1093/bioinformatics/btad056 代码:https://github.com/JU-HuaY/MFR 简介:近年来,深度学习已经成为药