之快专题

排序补充之快排的三路划分法
排序补充之快排的三路划分法 快排性能的关键点分析: 决定快排性能的关键点是每次单趟排序后,key对数组的分割,如果每次选key基本⼆分居中,那么快 排的递归树就是颗均匀的满⼆叉树,性能最佳。但是实践中虽然不可能每次都是⼆分居中,但是性能 也还是可控的。但是如果出现每次选到最⼩值/最⼤值,划分为0个和N-1的⼦问题时,时间复杂度为 O(N^2),数组序列有序时就会出现这样的问题,我们前⾯已经

为什么 GNU grep 如此之快?
为什么 GNU grep 如此之快? 编注:这是GNU grep的原作者Mike Haertel 在FreeBSD邮件列表中对 “GNU grep为什么比BSD grep要快” 所做的回答,下面是邮件正文内容: Gabor 您好, 我是GNU grep的原作者,同时也是一名FreeBSD用户,不过我一直使用的是-stable版本(也就是更老的版本),而没怎么关

计算机网络之快重传和快恢复以及TCP连接与释放的握手
快重传和快恢复 快重传可以让发送方尽早得知丢失消息, 当发送消息M1,M2,M3,M4,M5后,假如消息M2丢失,那么按照算法会发送对M2报文前一个报文M1的重复确认(M1正常接受到,已经发送了确认),然后之后收到M4,M5,也会发送两个重复确认,这样,规定只要收到3次重复确认,立即重传下一消息M3; 然后执行快恢复算法,发送方调整门限值为原来拥塞窗口值的一半,然后拥塞窗口值等于门限值,

七大排序算法之快排、冒泡
冒泡排序 思想:循环n次,交换左右两侧数据,外层每循环一次可以把无序中最大的(最小)的元素放到无序的最后面 时间复杂度: 平均:O(N^2)(一共循环:f(n) = (n-1)+(n-2)+...+2+1 = n*(n-1)/2 次) O(f(n)) = n^2(只留f(n)的最高项,并且去掉最高项的系数) 最好:O(N)(优化冒泡排序:排序数列本身就有序的情况
grep为何如此之快
下面是GNU grep的原作者MikeHaertel 在FreeBSD邮件列表中对 “GNU grep为什么比BSD grep要快” 这个问题所做的回答,解释了grep是如何进行快速搜索的,下面是邮件正文内容: why GNU grep is fast Mike Haertel mike at ducky.net Sat Aug 21 03:00:30 UTC 2010 •
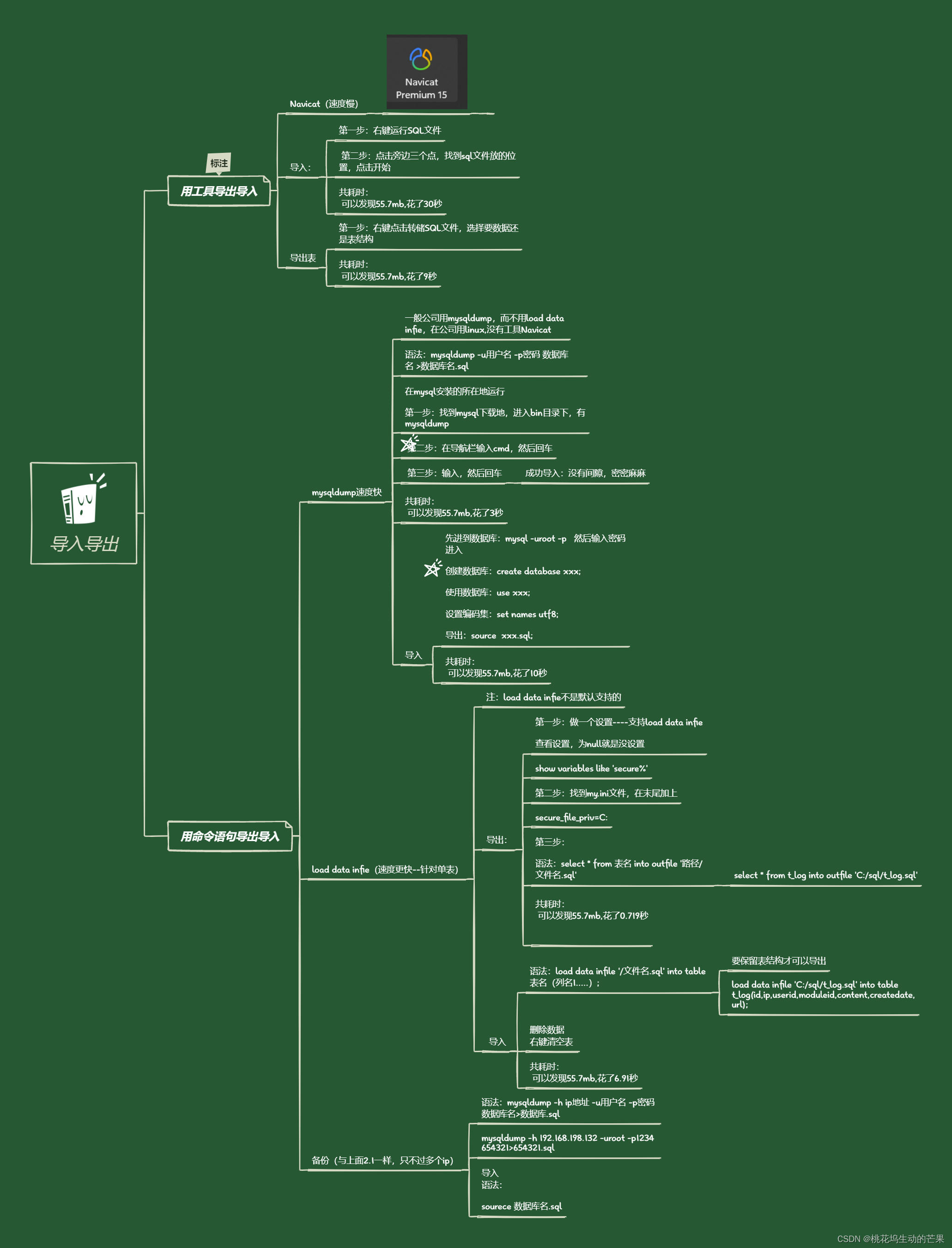
了解不同方式导入导出的速度之快
目录 一、用工具导出导入 Navicat(速度慢) 1.1、导入: 共耗时: 1.2、导出表 共耗时: 二、用命令语句导出导入 2.1、mysqldump速度快 导出表数据和表结构 共耗时: 只导出表结构 导入 共耗时: 2.2、load data infie(速度更快--针对单表) 导出: 共耗时: 编辑 导入 删除数据 编辑 共耗时: 三、备份
什么是Redis?Redis为什么如此之快?| 后端学习手册
随着互联网技术的进一步发展,各种类型的应用层出不穷,这导致在当今云计算、大数据盛行的时代,对性能有了更多的需求。 为了克服这一问题,NoSQL应运而生,它同时具备了高性能、可扩展性强、高可用等优点,受到广泛开发人员和仓库管理人员的青睐。 什么是Redis Redis是一个由ANSIC语言编写,性能优秀、支持网络、可持久化的Key-Value内存的NoSQL数据库,并提供多种语言的API。 Re
ClickHouse为何如此之快
针对ClickHose为什么很快的问题,基于对ClickHouse的基础概念之上,一般会回答是因为是列式存储数据库,同时也会说是使用了向量化引擎,所以快。上面两方面的解释也都能够站得住脚,但是依然不能够解释真正核心的原因。因为这些技术并不是秘密,市面上很多数据库同样使用了这些技术,但是依然没有ClickHouse这么快。我们可以从两外一个角度来探讨一番ClickHouse的快的秘密。 对于一般软
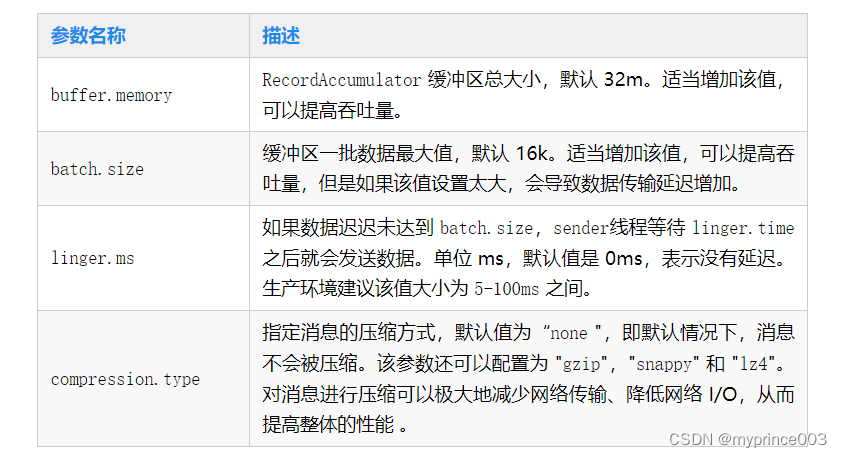
kafka为什么如此之快?
天下武功,唯快不破。同样的,kafka在消息队列领域,也是非常快的,这里的块指的是kafka在单位时间搬运的数据量大小,也就是吞吐量,下图是搬运网上的一个性能测试结果,在同步发送场景下,单机Kafka的吞吐量高达17.3w/s,不愧是高吞吐量消息中间件的行业老大。 那究竟是什么原因让kafka如此之快呢?这也是面试官非常喜欢问的问题。 四个原因 原因一:磁盘顺序读写 生产者发送数据到kafka
kafka为什么如此之快?
天下武功,唯快不破。同样的,kafka在消息队列领域,也是非常快的,这里的块指的是kafka在单位时间搬运的数据量大小,也就是吞吐量,下图是搬运网上的一个性能测试结果,在同步发送场景下,单机Kafka的吞吐量高达17.3w/s,不愧是高吞吐量消息中间件的行业老大。 那究竟是什么原因让kafka如此之快呢?这也是面试官非常喜欢问的问题。 四个原因 原因一:磁盘顺序读写 生产者发送数据到kafka