xverse专题
![[大模型]XVERSE-7B-chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/6217e32fe0a64f2c9a95361ec720c3c3.png#pic_center)
[大模型]XVERSE-7B-chat WebDemo 部署
XVERSE-7B-Chat为XVERSE-7B模型对齐后的版本。 XVERSE-7B 是由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),参数规模为 70 亿,主要特点如下: 模型结构:XVERSE-7B 使用主流 Decoder-only 的标准 Transformer 网络结构,支持 8K 的上下文长度(Context Length),能满足更长
![[大模型]XVERSE-MoE-A4.2B Transformers 部署调用](https://img-blog.csdnimg.cn/direct/0ce237e542bd4989bd1e903d7efa40c3.png#pic_center)
[大模型]XVERSE-MoE-A4.2B Transformers 部署调用
XVERSE-MoE-A4.2B介绍 XVERSE-MoE-A4.2B 是由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),使用混合专家模型(MoE,Mixture-of-experts)架构,模型的总参数规模为 258 亿,实际激活的参数量为 42 亿,本次开源的模型为底座模型 XVERSE-MoE-A4.2B,主要特点如下: 模型结构:XVERSE

大模型新篇章:元象XVERSE-Long-256K实现256K超长文本分析
引言 在人工智能的快速发展中,大模型技术始终是推动行业进步的重要力量。特别是在处理长文本上下文方面,长文本技术已成为衡量一个大模型技术成熟度的重要标准。近日,元象科技发布了全球首个256K上下文窗口长度的开源大模型——XVERSE-Long-256K,这一创新举措不仅填补了开源生态的空白,也标志着大模型技术在长文本处理能力上迈出了重要一步。 Huggingface模型下载:https://h
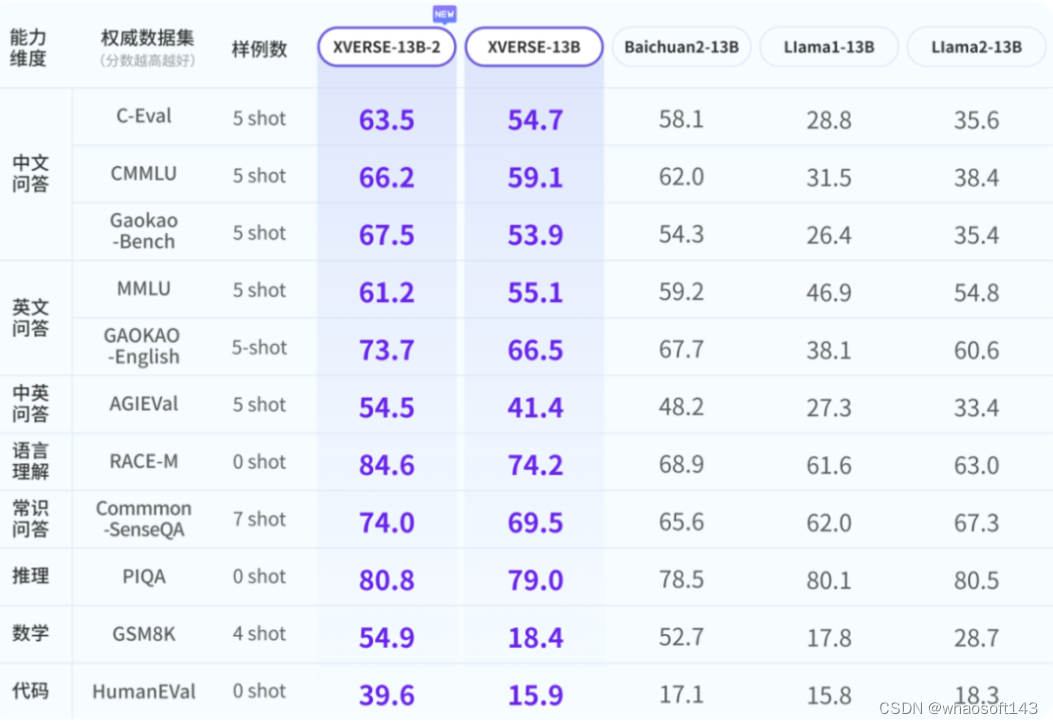
XVERSE-65B
大模型也太卷了吧, 国内此前开源了多个 70 到 130 亿参 数大模型,落地成果涌现,开源生态系统初步建立。随着智能体等任务复杂性与数据量的提升,业界与社区对更「大」模型的需求愈发迫切。国内最大开源模型来了,高性能无条件免费商用,元象 研究表明,参数量越高,高质量训练数据越多,大模型性能才能不断提升。而业界普遍共识是达到 500 到 600 亿参数门槛,大模型才能「智能涌现」,在多任务中展现强