xinference专题

本地部署Xinference实现智能体推理工作流(一)
提示:没有安装Docker的需要先提前安装好Docker 第一篇章 使用AutoDL平台快速部署xinference 备注:若使用AutoDL平台,以下过程使用无卡模型开机即可(省钱) 1. 下载Dify源码 Github下载Dify:https://github.com/langgenius/dify 2. 快速启动 启动 Dify 服务器的最简单方法是运行我们的 [docke

使用xinference部署自定义embedding模型(docker)
使用xinference部署自定义embedding模型(docker) 说明: 首次发表日期:2024-08-27官方文档: https://inference.readthedocs.io/zh-cn/latest/index.html 使用docker部署xinference FROM nvcr.io/nvidia/pytorch:23.10-py3# Keeps Python fr
![LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]](https://img-blog.csdnimg.cn/img_convert/b10128f1222cfef40c49ec90fbdfded4.png)
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架]
LLM 大模型学习必知必会系列(十二):VLLM性能飞跃部署实践:从推理加速到高效部署的全方位优化[更多内容:XInference/FastChat等框架] 训练后的模型会用于推理或者部署。推理即使用模型用输入获得输出的过程,部署是将模型发布到恒定运行的环境中推理的过程。一般来说,LLM的推理可以直接使用PyTorch代码、使用VLLM/XInference/FastChat等框架,也可以使用l
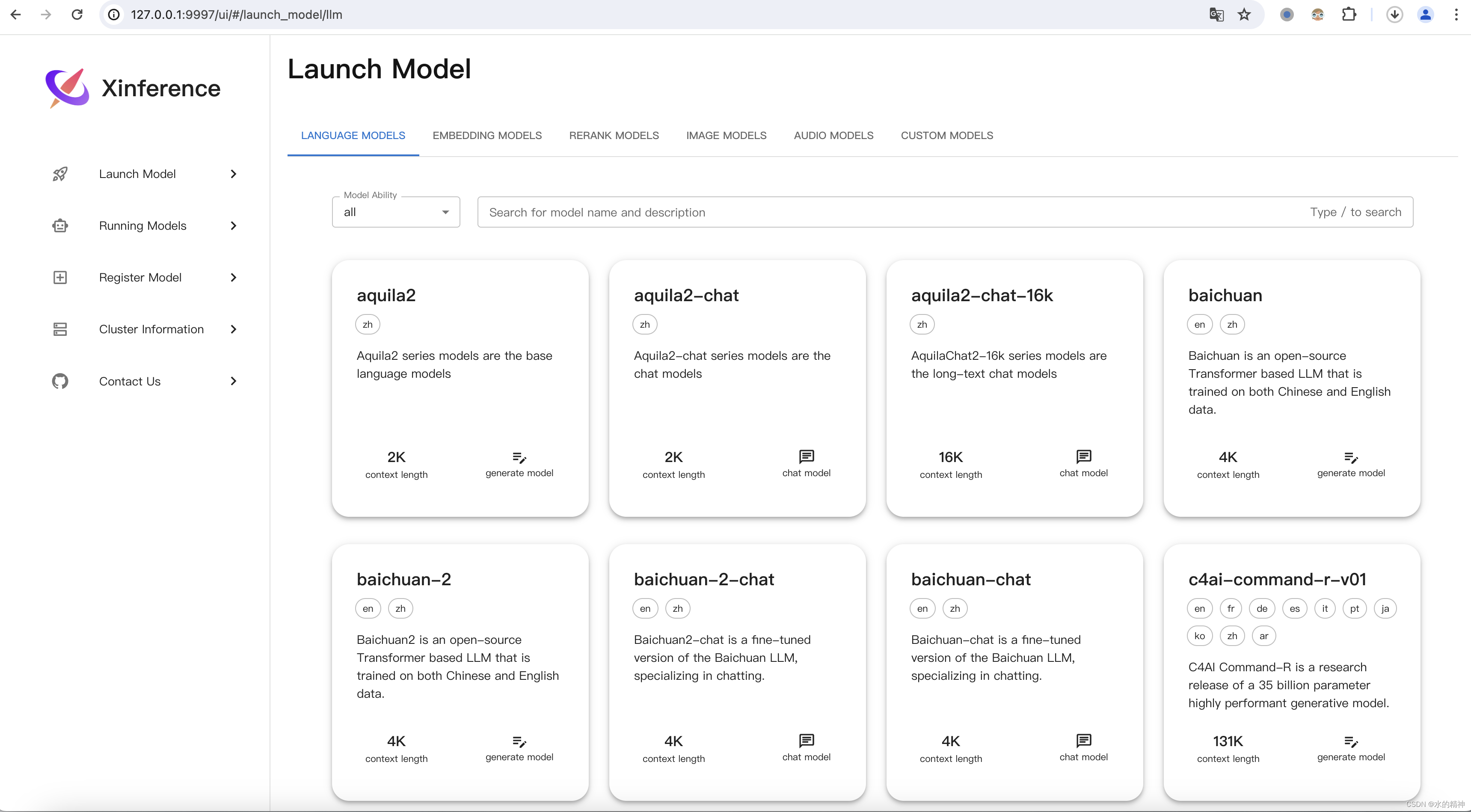
Mac M2 本地下载 Xinference
想要在Mac M2 上部署一个本地的模型。看到了Xinference 这个工具 一、Xorbits Inference 是什么 Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模
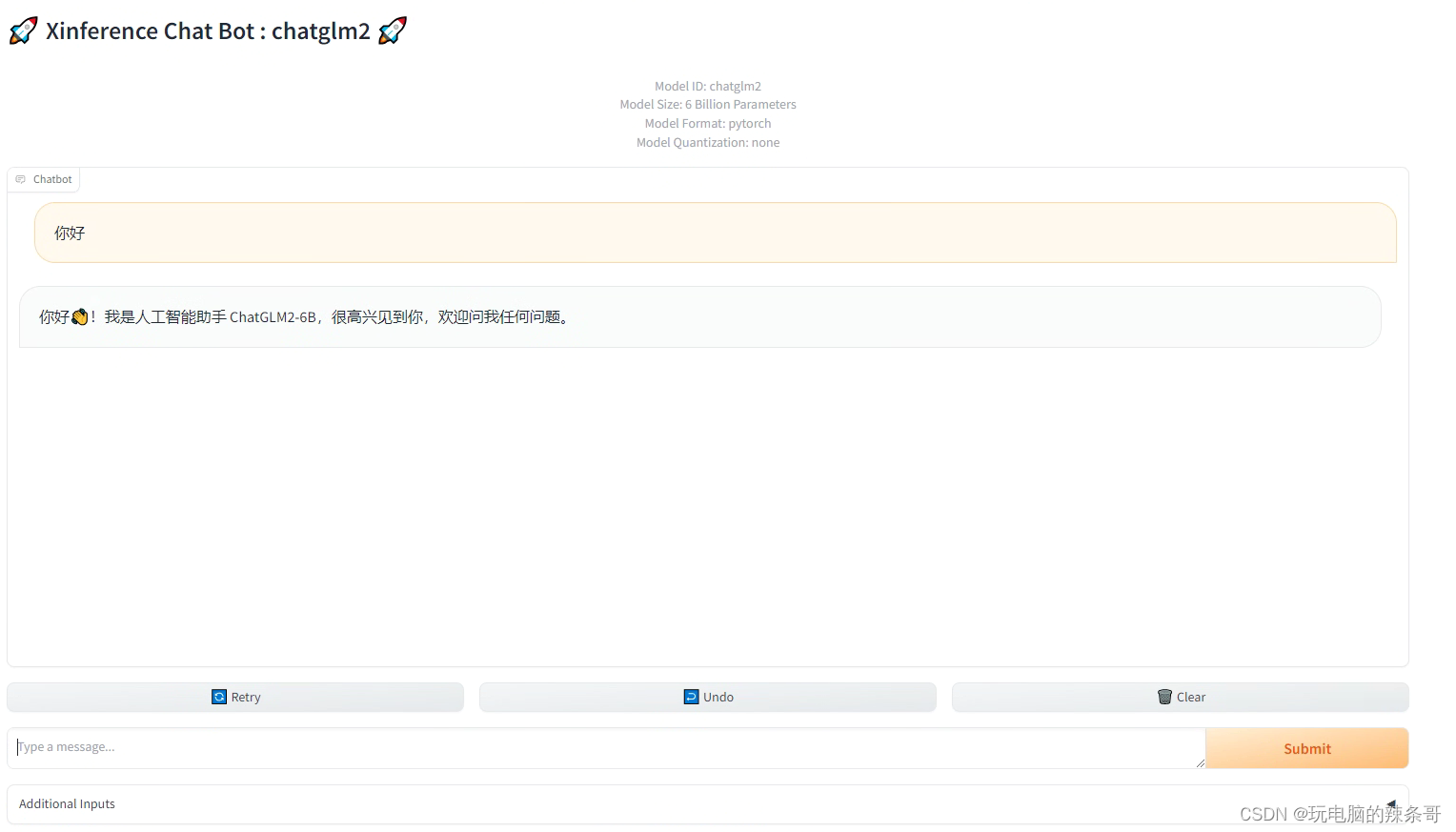
WSL2如何部署 Xinference
环境: WSL2 Ubuntu22.04 问题描述: WSL2如何部署 Xinference Xinference是一个用于加速和优化深度学习推理的平台。它提供了高性能、低延迟的推理解决方案,帮助开发者在生产环境中更高效地部署他们的深度学习模型。Xinference支持多种硬件平台,包括CPU、GPU和专用的AI加速器,同时提供了简单易用的API和工具,使用户能够轻松地集成和部署他们的
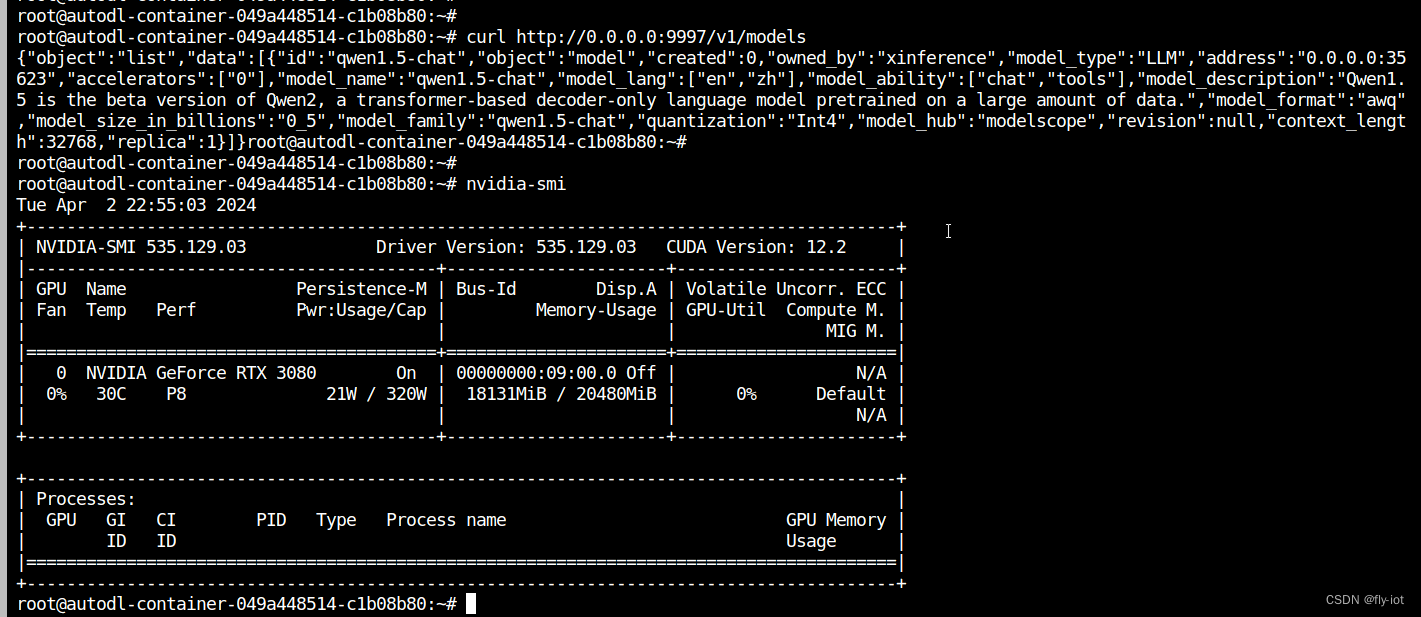
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
1,关于xinference Xorbits Inference (Xinference) 是一个开源平台,用于简化各种 AI 模型的运行和集成。借助 Xinference,您可以使用任何开源 LLM、嵌入模型和多模态模型在云端或本地环境中运行推理,并创建强大的 AI 应用。 Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(
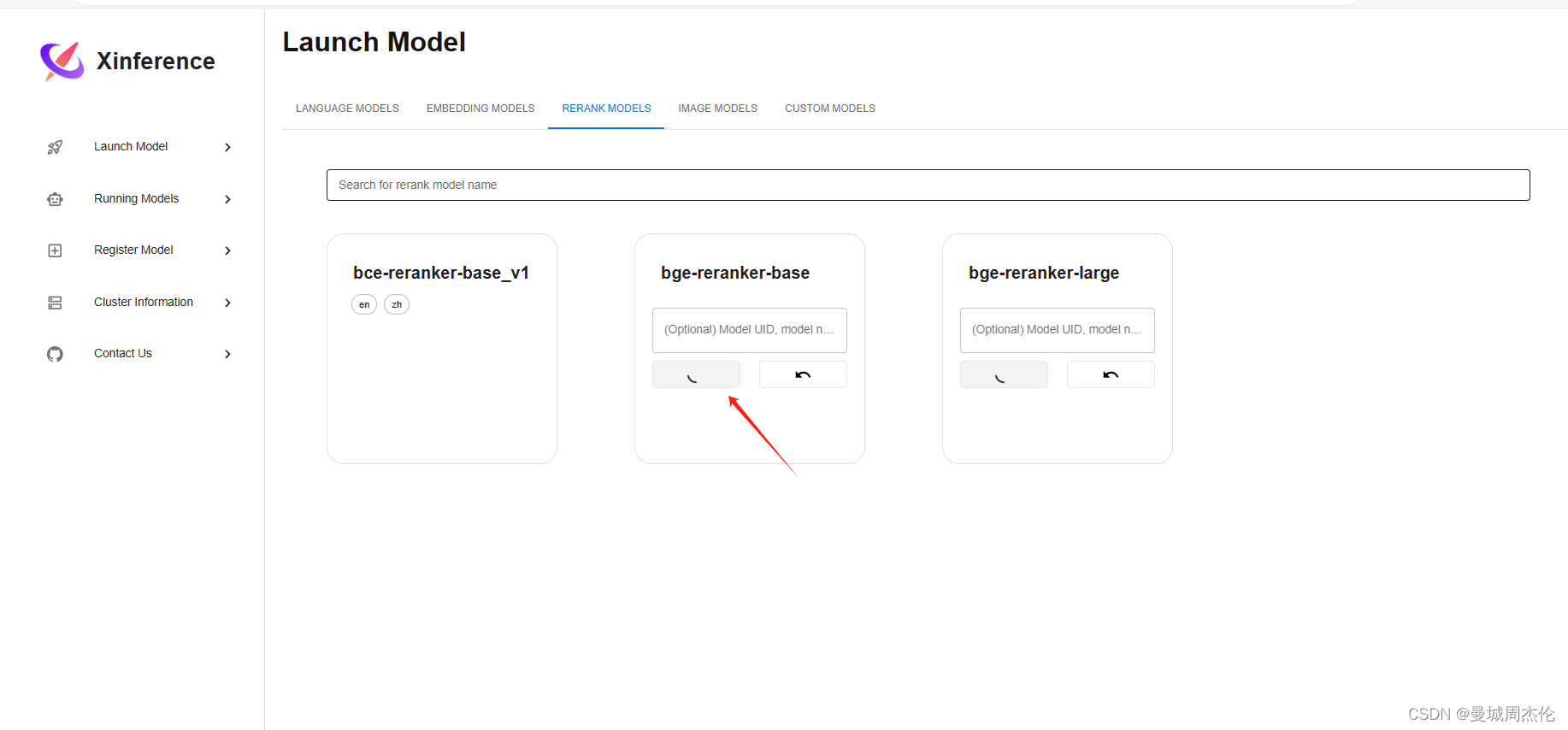
自然语言处理: 第十三章Xinference部署
项目地址: Xorbitsai/inference 理论基础 正如同Xorbits Inference(Xinference)官网介绍是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 X

FastGPT + Xinference + OneAPI:一站式本地 LLM 私有化部署和应用开发
Excerpt 随着 GPTs 的发布,构建私有知识库变得无比简易,这为个人创建数字化身份、第二大脑,或是企业建立知识库,都提供了全新的途径。然而,基于众所周知的原因,GPTs 在中国的使用依然存在诸多困扰和障碍。因此,在当… 随着 GPTs 的发布,构建私有知识库变得无比简易,这为个人创建数字化身份、第二大脑,或是企业建立知识库,都提供了全新的途径。然而,基于众所周知的原因,GPTs