vqgan专题
![[WIP]Sora相关工作汇总VQGAN、MAGVIT、VideoPoet](https://img-blog.csdnimg.cn/direct/22aa1d0fcceb4c4081e72bd8d52d6907.png)
[WIP]Sora相关工作汇总VQGAN、MAGVIT、VideoPoet
视觉任务相对语言任务种类较多(detection, grounding, etc.)、粒度不同 (object-level, patch-level, pixel-level, etc.),且部分任务差异较大,利用Tokenizer核心则为如何把其他模态映射到language space,并能让语言模型更好理解不同的视觉任务,更好适配LM建模方式,目前SOTA工作MAGVIT-v2,VideoPo

TAMING TRANSFORMERS FOR HIGH-RESOLUTION IMAGE SYNTHESIS (A.K.A #VQGAN)
Paper name TAMING TRANSFORMERS FOR HIGH-RESOLUTION IMAGE SYNTHESIS (A.K.A #VQGAN) Paper Reading Note Paper URL: https://arxiv.org/abs/2012.09841 Project URL: https://compvis.github.io/taming-trans

【GitHub】VQGAN+CLIP代码从零开始复现
论文地址 GitHub地址 论文讲解 从开放领域的文本提示中生成和编辑图像是一项具有挑战性的任务,到目前为止,需要昂贵的和经过专门训练的模型。我们为这两项任务展示了一种新的方法,它能够通过使用多模态编码器来指导图像的生成,从具有显著语义复杂性的文本提示中产生高视觉质量的图像,而无需任何训练。我们在各种任务上证明了使用CLIP来指导VQGAN产生的视觉质量比之前不太灵活的方法如
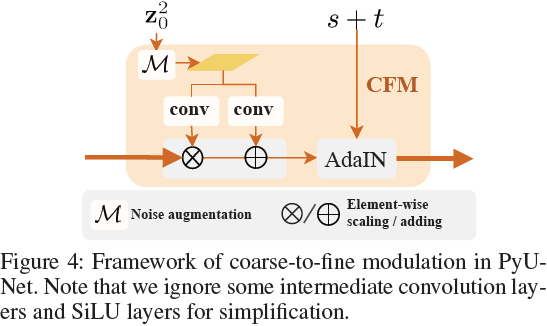
(2023|AAAI,MS-VQGAN,分层扩散,PyU-Net,粗到细调制)Frido:用于复杂场景图像合成的特征金字塔扩散
Frido: Feature Pyramid Diffusion for Complex Scene Image Synthesis 公众号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 2. 基础 3. 方法 3.1 学习多尺度感知潜在 3.2 特征金字塔潜在扩散模型 4. 实验 4.1 数据集和评估