vera专题
【自然语言处理】【大模型】VeRA:可调参数比LoRA小10倍的低秩微调方法
VeRA:可调参数比LoRA小10倍的低秩微调方法 《VeRA:Vector-based Random Matrix Adaptation》 论文地址:https://arxiv.org/pdf/2310.11454.pdf 相关博客 【自然语言处理】【大模型】VeRA:可调参数比LoRA小10倍的低秩微调方法 【自然语言处理】【大模型】MPT模型结构源码解析(单机版) 【自然
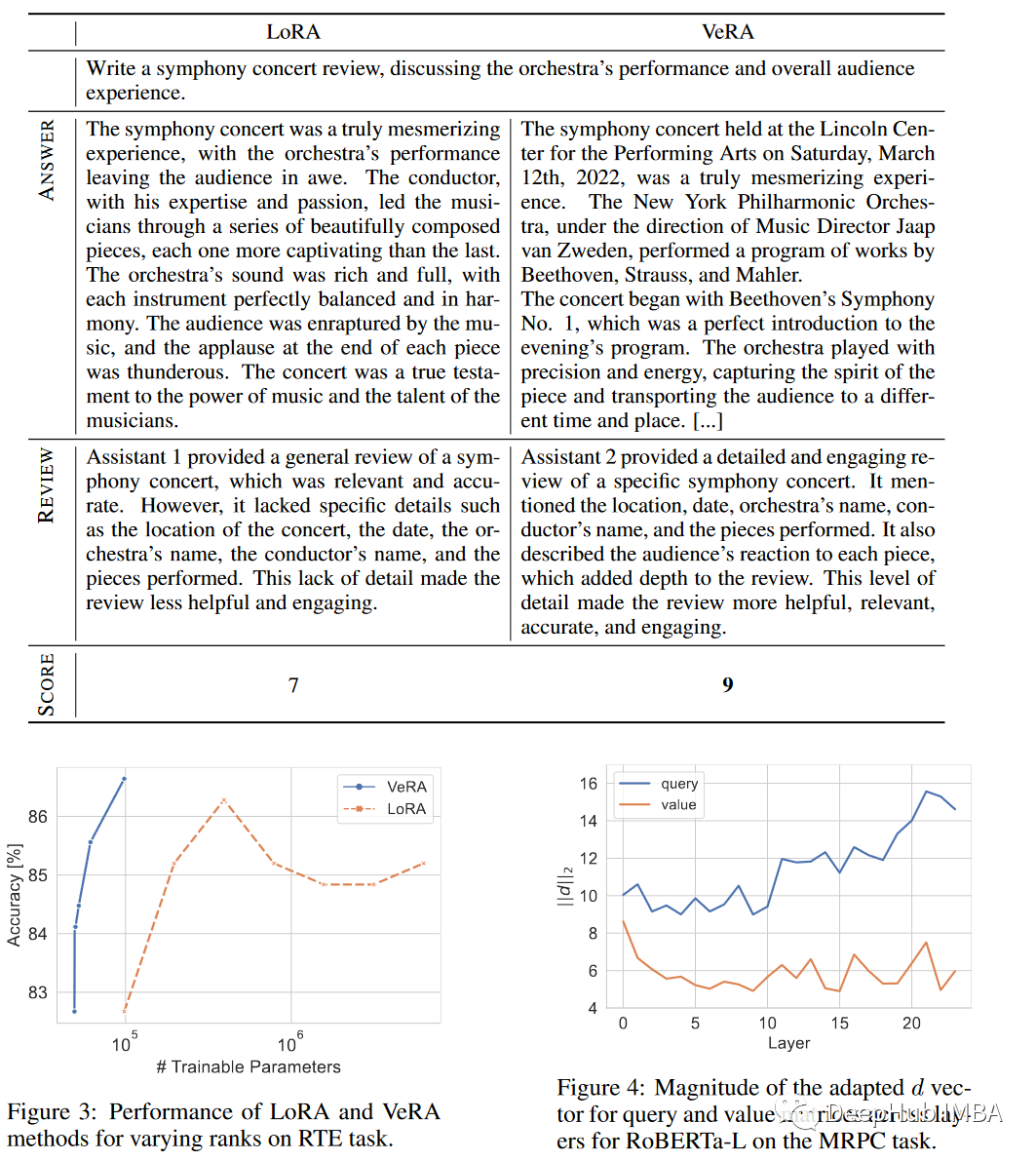
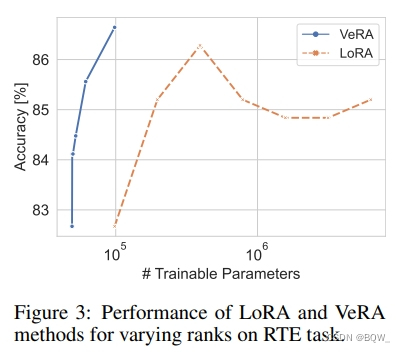
VeRA: 性能相当,但参数却比LoRA少10倍
2022年的LoRA提高了微调效率,它在模型的顶部添加低秩(即小)张量进行微调。模型的参数被冻结。只有添加的张量的参数是可训练的。 与标准微调相比,它大大减少了可训练参数的数量。例如,对于Llama 27b, LoRA通常训练400万到5000万个参数,这比标准微调则训练70亿个参数药效的多。还可以使用LoRA来微调量化模型,例如,使用QLoRA: 虽然LoRA可训练参数的数量可能比模型参