utf8专题

批量文件编码转换用python实现的utf8转gb2312,vscode设置特殊文件的默认打开编码
批量文件编码转换用python实现的utf8转gb2312, 任意编码之间的相互转换都是可以的.改一下下面的参数即可 convert.py文件内容如下 import osimport globimport chardet#检测文件编码类型def detect_file_encoding(file_path):with open(file_path, 'rb') as f:data = f

如何设置 zend studio 默认编码为UTF8
今天用zend studio 打开文件时发现为乱码,这肯定是编码出了问题,我看了一下果然是编码出了问题,默认的是以GBK编码方式打开,我换utf8编码打开就好了,换编码打开的方法是: 1、点击工具栏中的edit, 找到set encoding··· 将编码改为utf8即可。 这样改明显很麻烦,怎么把默认编码设置成为utf8呢? 1 、依次打开 window->

whose UTF8 encoding is longer than the max length 32766
问题描述:java.lang.IllegalArgumentException: Document contains at least one immense term in field=“cf_jg.keyword” (whose UTF8 encoding is longer than the max length 32766) 原因:设置为keyword类型的字段,插入很长的大段内容后,报
utf8和unicode编码的关系
UTF8 == Unicode Transformation Format – 8 bit 是Unicode传送格式。即把Unicode文件转换成BYTE的传送流。 UTF8流的转换程序: Input: unsigned integer c - the code point of the character to be encoded (输入一个unicode值) Output: byt

设置mysql5.7编码格式为UTF8
为了解决这个问题,各种百度,试了好多种方法,也看了好多博客,这一片博客解决了我的问题。 <span style="font-family:SimSun;font-size:18px;">http://blog.csdn.net/u013474104/article/details/52486880;在此总结一下以免下次再出现问题走弯路。</span>

在Mysql数据库中执行函数报错: Illegal mix of collations (gbk_chinese_ci,IMPLICIT) and (utf8_general_ci,COERCIBLE
SQLSTATE[HY000]: General error: 1267 Illegal mix of collations (utf8_general_ci,IMPLICIT) and (gb2312_chinese_ci,COERCIBLE) for operation ‘=’ 在操作MySQL数据库时,报“ error code [1267]; 在Mysql数据库中执行函数报错: Illeg
javac编译错误: 编码UTF8/GBK的不可映射字符
本文出处: http://blog.csdn.net/leytton/article/details/52740171 Linux下为UTF-8编码,javac编译gbk编码的java文件时,容易出现“错误: 编码UTF8的不可映射字符” 解决方法是添加encoding 参数:javac -encoding gbk WordCount.java Windows下为G
MySQL 字符集utf8、utf8mb3、utf8mb4
首先想要了解MySQL的字符集,就需要去官方文档看看字符集是如何介绍的。英语不错的话,看官方文档应该是没问题。在搜索框里搜一下就可以找到相关的解释。我就在这里整理一下,以便后期查看。字符集在官方文档下面这一章节:Chapter 10 Character Sets, Collations, Unicode https://dev.mysql.com/doc/refman/5.6/en/charse
优化C++ utf8,gbk,unicode编码间的转换函数
好久没写博客了,不是太忙,是太懒了。。。 最近都在重构公司项目上的代码,然后就发现有部分函数的运行方式可以优化。这些函数的运行的运行方式都是先new出一堆内存,使用,最后delete掉。我就想,可不可以通过静态局部变量来重复使用已经new了的动态内存,以达到优化代码的运行的目的?然后我就用visual studio 2017进行了测试,下面是我的测试代码: #include <random>
javascript 中字符串转化utf8字节数组, 然后在将字节数组转化十六进制字符串
https://www.cnblogs.com/han-guang-xue/p/14386666.html 1. Buffer 是用来处理流操作的 2. 字符串转化utf8字节数组, 然后在将字节数组转化十六进制字符串 /** 将字符串转化为utf-8字节 */function ToUTF8(str) {var result = new Array();var k = 0;for (var
Hive建表乱码解决--设置编码格式UTF8
1.创建Hive元数据库 Hive元数据存储在MySQL中,因此需要进入MySQL中创建Hive元数据库;若已存在Hive元数据库,则修改元数据库字符格式 hive建库语句: create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci; 只有修改编码后才加入的中文注释才会正常显示 ,修改编码前已经存在的中文注释会乱码
UTF8二进制及明文字符窜转化
<?php /***********本程序由云客编写。有空的时候承接php软件开发 *满足一下新手们的好奇心,看看UTF-8的二进制是什么样子滴 ****************************/ define("b", "<br>"); $a = "FE"; $a1 = "FF"; $s = 16; $e = 2; echo $s . "进制的" . $a . "表示为" . $e .
ExcelForEcms7.0_utf8 V1.0 全功能版
360云盘现已不能访问 请加QQ群203286137到共享空间下载,加群请注明来由,否则拒入 插件简介: ExcelForEcms是一个专门为帝国cms系统开发的插件,用于Office Excel文档和ecms系统之间的数据导入、导出、批量修改。支持所有系统模型,不修改任何帝国系统文件,完全遵循帝国中设定的用户权限,多管理员权限配置;特别适合企业站的应用,数据维护人员无需是网站管理员,如大量
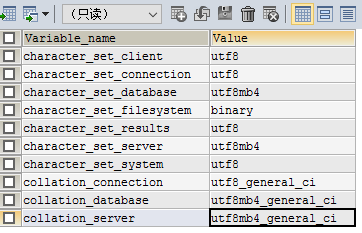
全面了解mysql中utf8和utf8mb4的区别
一.简介 MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。 二.内容描述 那上面说了既然utf8能够存下大部分中文汉字,那为什么还要
linux操作系统下的mysql编码设置为utf8
版本: 在linux命令行下输入: cat /etc/issue Ubuntu 12.04 LTS \n \l </pre><pre name="code" class="plain">mysql版本 mysql> status--------------mysql Ver 14.14 Distrib 5.5.37, for debian-linux-gnu (x86_64)
Centos下mysql数据库安装、创建数据库、utf8编码设置、外部访问授权、导入sql执行、开机启动(系列2)
1.设置root用户密码 创建完mysql数据库需要登录进mysql数据库,需要用户名和密码,而初始时候需要自己设定root的密码 更改root密码 mysqladmin -u root password 'yourpassword' 2.连接mysql数据库 mysql -u root -p 然后提示输入密码,输入上面设置的密码即可。 或者my
c++ utf8 string iterator
一边学习一遍糊了一个,代码质量不高,but it works #include <windows.h>#include <iostream>#include <string>using namespace std;class stringIter {private:string &str;public:class iterator {private:string &str;string::it
Python2和Python3对utf8的实现方式有什么区别?
`# -*- coding: utf8 -*-` 是一个特殊的文件头部注释,通常出现在Python 2的源代码文件的开头。这个注释告诉Python解释器,该源文件使用的是UTF-8编码。这对于包含非ASCII字符(例如中文字符、特殊符号等)的Python源代码文件来说非常重要。 在Python 2中,默认的源代码编码是ASCII。如果你试图在源代码文件中使用非ASCII字符而没有指定编码,
GBK和UTF8之间的转换 C语言
GBK和UTF8之间的转换可以使用MultiByteToWideChar和WideCharToMultiByte两个API,方法是先把它们转换为中间编码Unicode,再转换为对应的编码即可。 #include < stdio.h > #include < windows.h > // GBK编码转换到UTF8编码 int GBKToUTF8
织梦cms官方DedeCMS-V5.7.114-UTF8文件结构
织梦的安全性问题是值得关注的,用户的客户比较多,网站被挂马也是层从不穷。 基于官方最新版本DedeCMS-V5.7.114-UTF8的目录结构和无任何调整的情况下,汇总的所有文件及目录结构。 {根目录}/tags.php{根目录}/index.php{根目录}/robots.txt{根目录}/license.txt{根目录}/favicon.ico{根目录}/uploads/inde
[ERROR] Table gym_api_utf8/membership_students contains 2 indexes inside InnoDB, which is different
1. 问题描述 alter table add index(xxx);时出现此问题,mysql服务版本5.5。 新特性“Fast index creation in Innodb”未出现以前,Innodb中创建索引的流程如下: 通过创建一个新的空的带有要创建索引的表,然后拷贝存在的行到新表中,同时更新索引,当此时key没有排序时插入条目极慢。在所有的行都被拷贝完成以后,旧表被删除,新表被改名。
织梦cms官方DedeCMS-V5.7.114-UTF8文件后缀汇总
织梦的安全性问题是值得关注的,了解安全性问题,需要从文件入手。 基于官方最新版本DedeCMS-V5.7.114-UTF8的目录结构和无任何调整的情况下,汇总的文件后缀。 phptxticohtmlgifcsspngswfjpgjshtmincwoffsvgotfeotttfxmldatdiczipmap 以上是所有包括的官方源码所提供的文件后缀。
UTF8、ASC、其他编码字符串检测
int IsUTF8(const char* str, int length) { bool allAsc = true;//是否为ASC unsigned char ch;//当前字节 int charByte = 0;//某个字符编码字节数 int i = 0; while( ch = str[i++]) { if( ((ch & 0x80) == 0) && charByte ==
移除utf8+BOM格式的html文件头有一行空格的问题
最近在改模板时,发现页面最开头地方多了一行空白行,真是苦撒老夫,查看源码出现,这是什么鬼?? 究其原因,是文件格式的问题,保存时一不小心保存为了utf8+bom格式了, 什么事bom: 这种编码方式一般会在windows操作系统中出现,比如WINDOWS自带的记事本等软件,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不 可见的字符(0xEF 0xBB 0x
【字符编码】‘utf8’ codec can’t decode byte 0xa1
办法1: 文件头部增加代码,如下 #!/usr/bin/env python# coding=utf-8 办法2: 用 codecs打开文件,如下 codecs.open() 办法3: 用 utf8编码打开文件,如下 with open(file, 'r', encoding='utf-8') as f: 办法4: 用 ISO-8859-1 编码打开文件(应用于