urlopen专题

Python 2.7.3 AttributeError: 'module' object has no attribute 'urlopen'
在使用下面语句时候出现 from urllib import urlopenwebpage = urlopen('http://www.python.org')AttributeError: 'module' object has no attribute'urlopen' 我是ubuntu 12.04 + 自带Python 2,7.3 一开始以为是什么Python和Pytho

【Python】请求网页数据(urlopen)
提要: 1.urlopen(URL) 可以返回URL对应网页的数据 贴图: 代码: #encoding: utf-8from urllib import requestres = request.urlopen("http://47.94.171.17:8080")print(res.read()) 返回结果: G:\PythonProject\Demo1\venv\
python3.x module 'urllib' has no attribute 'urlopen' 或 ‘urlencode’问题解决方法
问题 最近在使用Python的第三方模块 urllib 中的urlencode方法将字典编码,用于提交数据给url等操作,发现urllib 下并没有urlencode 和openurl,原来是因为在python3和python2下urllib模块中提供的urlencode 和openurl 位置不同。 解决 最好的解决办法就是找到 urllib 库文档 python2 python2

urllib2.urlopen超时未设置导致程序卡死
没有设置timeout参数,结果在网络环境不好的情况下,时常出现read()方法没有任何反应的问题,程序卡死在read()方法里,搞了大半天,才找到问题,给urlopen加上timeout就ok了,设置了timeout之后超时之后read超时的时候会抛出socket.timeout异常,想要程序稳定,还需要给urlopen加上异常处理,再加上出现异常重试,程序就完美了。 import urll

Python 关于 urllib.request.urlopen()的错误
在刚开始学习python准备学习爬虫时在使用pycharm编译出现了错误 这是源码: #!usr/bin/pythonimport urllib.requesturl = "http://www.baidu.com"get = urllib.request.urlopen(url).read()print(get) 这个本来就很简单但是出现了以下错误: C:
![urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certify...](https://img-blog.csdnimg.cn/4cce1de4b7bc48d39e1f3a07a6251c0f.png)
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certify...
我是在下载数据集时出现的错误 找到request.py,输入红框代码即可
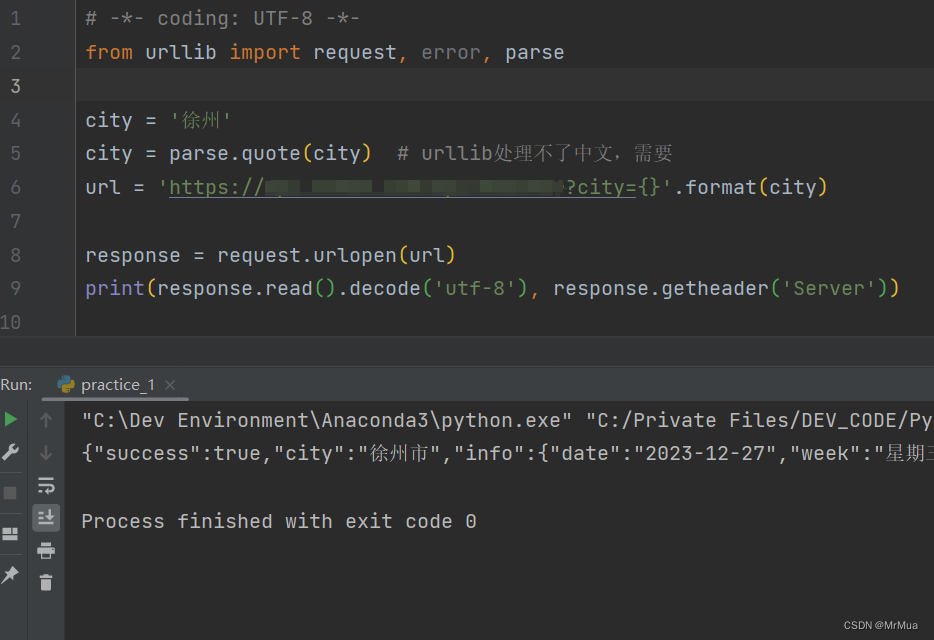
处理urllib.request.urlopen报错UnicodeEncodeError:‘ascii‘
参考:[Python3填坑之旅]一·urllib模块网页爬虫访问中文网址出错 目录 一、报错内容 二、报错截图 三、解决方法 四、实例代码 五、运行截图 六、其他UnicodeEncodeError: 'ascii' codec 问题 一、报错内容 UnicodeEncodeError: 'ascii' codec can't encode characters in p

不要直接使用urllib2.urlopen直接发送http请求
今天在测试netty http接口时发现,如果使用urslib2发送请求不会有kepp-alive效果。 测试代码 import urllib2print urllib2.urlopen("http://localhost:8989/blogQueryService/toDate?param1=1360812238.0")from urllib2 import Httph = Http(

爬虫证书问题,urllib.request.urlopen(),无法正常响应
urllib.request.urlopen(), 无法正常响应 运行以下代码即可 # 证书问题import sslssl._create_default_https_context = ssl._create_unverified_context
![【nltk_data】报错Resource xxxx not found.和Error loading omw: <urlopen error [Errno 11004]解决](https://img-blog.csdnimg.cn/684377e97a354689ac328586f45b02f5.png)
【nltk_data】报错Resource xxxx not found.和Error loading omw: <urlopen error [Errno 11004]解决
Resource punkt not found. 下载完整包 地址:https://github.com/nltk/nltk_data 解压缩到python安装地址的share文件夹中。仍然会报错: 使用他给的命令下载 报错,或许需要科学上网。 观察一下这个报错缺少的文件,去share\nltk_data文件夹下查看,发现它需要的tokenizers\punkt文件夹在packages里,把
![[nltk_data] Error loading stopwords: <urlopen error [WinError 10054]](https://img-blog.csdnimg.cn/482933ab62254fb5b19232ef99b2d975.png)
[nltk_data] Error loading stopwords: <urlopen error [WinError 10054]
报错提示: >>> import nltk >>> nltk.download('stopwords') 按照提示执行后 [nltk_data] Error loading stopwords: <urlopen error [WinError 10054] 找到路径'C:\\Users\\EDY\\nltk_data',如果没有nltk_data文件夹,在C:\\Users\\
[nltk_data] Error loading stopwords: <urlopen error [WinError 10054]
报错提示: >>> import nltk >>> nltk.download('stopwords') 按照提示执行后 [nltk_data] Error loading stopwords: <urlopen error [WinError 10054] 找到路径'C:\\Users\\EDY\\nltk_data',如果没有nltk_data文件夹,在C:\\Users\\