unicodedecodeerror专题

解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 108: ordinal not in range(128
1.问题描述:一个在Django框架下使用Python编写的定时更新项目,在Windows系统下测试无误,在Linux系统下测试,报如下错误: ascii codec can't decode byte 0xe8 in position 0:ordinal not in range(128) 2.原因分析:字符问题。在Windows系统转Linux系统时,字符问题很容易出现。 3.解决办

《Python开发 - Python疑难杂症》Pyinstaller打包报错【UnicodeDecodeError: ‘utf-8‘ codec can‘t decode】分析与解决
1报错情景描述 笔者在使用PyQt5写了个程序后,使用Pyinstaller打包,出现以下错误: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xce in position 110: invalid continuation byte 2报错分析 从报错代码能够看出,编码问题导致的程序出错,解决办法就是修改编码方式。 3解决

aiohttp遇到非法字符的处理(UnicodeDecodeError: 'utf-8' codec can't decode bytes in position......)
这个问题困扰了我将近一天时间,如果使用text()函数会一直报“UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 24461-24462: invalid continuation byte”的错误,如果使用read()函数以二进制输出在后面解析的时候中文是乱码,网上查了很多资料,主要也是自己的疏忽自己看了源码,一直纠
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc9 in position 167
在用urllib.request库的时候一部小心就会碰到 url = "http://money.163.com/special/pinglun/"data_byte = urllib.request.urlopen(url).read()data = data_byte.decode('UTF-8')print(data) 报错: UnicodeDecodeError: 'utf-

Python遇到 UnicodeDecodeError
<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255);">这是因为.py文件保存的格式有问题。可以在第一行添加注释</span> # -*- coding: utf-8 -*-
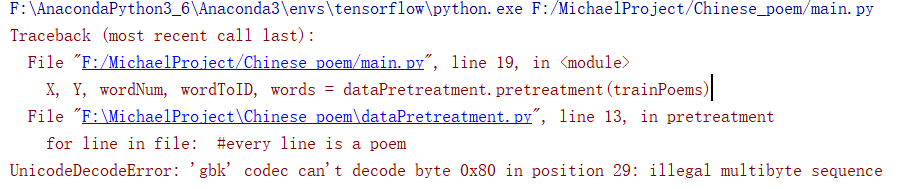
问题 | UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 29解决办法
github:https://github.com/MichaelBeechan CSDN:https://blog.csdn.net/u011344545 python读文件: file = open(filename, "r") for line in file: #every line is a poem#print(line)title, poem = line.strip().

UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence
pycharm报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence 解决办法: 然后: 就好了!
python读取文件时提示UnicodeDecodeError: 'gbk' codec can't decode byte 0x80 in position 205: illegal multi
解决办法1. FILE= open('order.log','r', encoding='UTF-8') 解决办法2 FILE= open('order.log','rb')

解决UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5
Python的str默认是ascii编码,和unicode编码冲突,就会报这个标题错误。那么该怎样解决呢? 通过搜集网上的资料,自己多次尝试,问题算是解决了,在代码中加上如下几句即可。 import sysreload(sys)sys.setdefaultencoding('utf8')
UnicodeDecodeError: 'utf8' codec can't decode bytesnbsp
▼ 编码问题真的是个很常见且困扰的问题: 原文是ansi编码,(windows下默认编码),换到linux下工作,需要转为utf8编码,文件多所以写了个小程序, 其中执行到这:outfile.write(line.encode('utf-8')),会报错: UnicodeDecodeError: 'utf8' codec can't decode bytes in positio
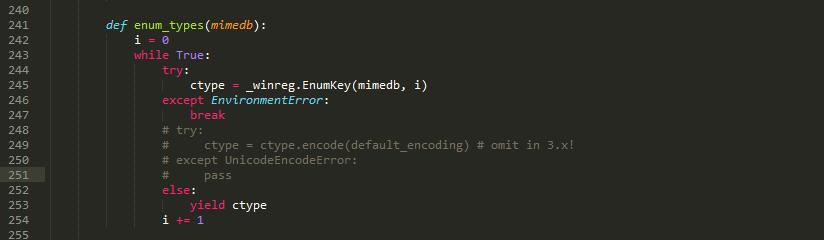
UnicodeDecodeError: 'ascii' codec can't decode byte 0Xb0 in postion 1: ordinal not in range(128)
Python 安装一些package包时会提示:UnicodeDecodeError 安照网上的方法解决方案: 在C:\Python27\Lib 里面找到 mimetypes.py 注释或者删除第249行的那一片断代码。

UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xd7
安装mamba时报错 检查报错原因: file -i ~/.bashrcfile -i ~/.profile 发现bashrc的编码不正确 对编码格式进行修改 iconv -f ISO-8859-1 -t UTF-8 ~/.bashrc > ~/.bashrc.utf8mv ~/.bashrc.utf8 ~/.bashrccp ~/.bashrc ~/.bashrc.backup
python 3以上版本使用pickle.load读取文件报UnicodeDecodeError: 'ascii' codec can't decode byte 0x8d in position 1
源码中 resource_val = pickle.load(opened_resource) 改为 resource_val = pickle.load(opened_resource,encoding='iso-8859-1')
解决Python:UnicodeDecodeError:‘utf-8‘ codec can‘t decode byte 0xe5 in position 1797: invalid continuat
今天在写脚本时,本来昨天可以运行的代码突然报错: UnicodeDecodeError:'utf-8' codec can't decode byte 0xe5 in position 1797: invalid continuation 然后查了很多资料,都说是编码的问题,但我查看了所有文件以及源码的编码,都没有问题,后来找到了一个文章解决了问题 打开你报错的utils文件 修改函数参数
(20200720已解决)UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0x80 in position 7: invalid start b
问题描述 如题 解决方案 因为pickle文件写入是binary格式,因此读取的时候也需要用binary格式。 return = open("picklefile", 'rb') 出现另外一个问题: _pickle.UnpicklingError: A load persistent id instruction was encountered,but no persistent_load

【python】UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte
header中干掉 "Accept-Encoding": "gzip, deflate, br", 注意:
UnicodeDecodeError ascii codec can't decode byte 0xe5 in position 0 ordinal not in range(128)
运行python程序时出现以下错误: UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0xe5 in position 0: ordinal not in range(128) 解决办法: 摘自:https://stackoverflow.com/questions/21393758/unicodedecodeerror-ascii-co
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd1 in position 0: invalid continuation byte解决办法
出现这个问题,首先就是检查源文件的编码方式是不是utf8,这个可以用vscode或者notepad++打开后直接看编码方式,当然也可以用其他方法查看。如果不是utf8编码方式,则自然不能用utf8解码,对此只需要把编码参数设置成对应的编码方式即可。 当然,上面说的是最简单基本的解决方式,一般遇到上述问题,如果用各种编辑软件打开源文件后显示的编码方式就是utf8,但是尽
从huggingface下载模型像本地加载但是UnicodeDecodeError
我自己是在Linux下出现了这个问题 原文:https://github.com/huggingface/transformers/issues/13674 The path for the AutoModel should be to a directory pointing to a pytorch_model.bin and to a config.json. Since you’re

UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb8 in position 0: invalid start byte的解决方法
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb8 in position 0: invalid start byte的两种解决方法 初学Python,为了完成学习任务边学习Python基础知识,边应用,最近在学习jieba分词,将指定路径下的文本文件中的内容进行分词并将分好词的内容保存到指定路径下的TXT文件中,从网上找了一段比较容易
python: UnicodeDecodeError: 'ascii' codec can't decode byte 0xe2 in position 20: ordinal not in rang
resolution:http://stackoverflow.com/questions/10561923/unicodedecodeerror-ascii-codec-cant-decode-byte-0xef-in-position-1 str.decode('UTF-8')

pandas读文件时中UnicodeDecodeError常用解决方案
如果我们遇到UnicodeDecodeError,一般而言是因为编码错误。所以尝试其他编码是个不错的选择。 但一一尝试速度较慢,我们不妨使用chardet库和pandas读文件时encoding_errors='ignore'共同解决问题。 chardet库可以帮我们检测可能的编码。 import pandas as pdimport numpy as npimport chardet#
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd4 in position 2: invalid continuation byte
代码如下: f = open("啦啦啦.txt", "r",encoding="utf-8")t = f.read()f.close() 改正方法: f = open("啦啦啦.txt", "r")t = f.read()f.close() 类似的其他问题的总结:https://blog.csdn.net/sun9979/article/details/89047129
UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 20: illegal multibyte sequence
代码如下: f = open("哈哈哈.txt", "r")t = f.read()f.close() 改正方法: f = open("哈哈哈.txt", "r",encoding="utf-8") #添加encoding参数 t = f.read()f.close() 类似的其他问题的总结:https://blog.csdn.net/sun9979/article/detai
CentOS 中使用yum出现的“UnicodeDecodeError: 'ascii' codec”问题解决方法
问题 新装了CentOS 6.5系统,打算使用yum安装程序是出现了如下错误: Loading mirror speeds from cached hostfileTraceback (most recent call last):File "/usr/bin/yum", line 29, in <module>yummain.user_main(sys.argv[1:], exit_

response.read().decode() UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xc6 in position 80: i
错误提示 info = response.read().decode() UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc6 in position 80: invalid continuation byte 解决方案 info = response.read().decode("utf8","i