tuijian专题
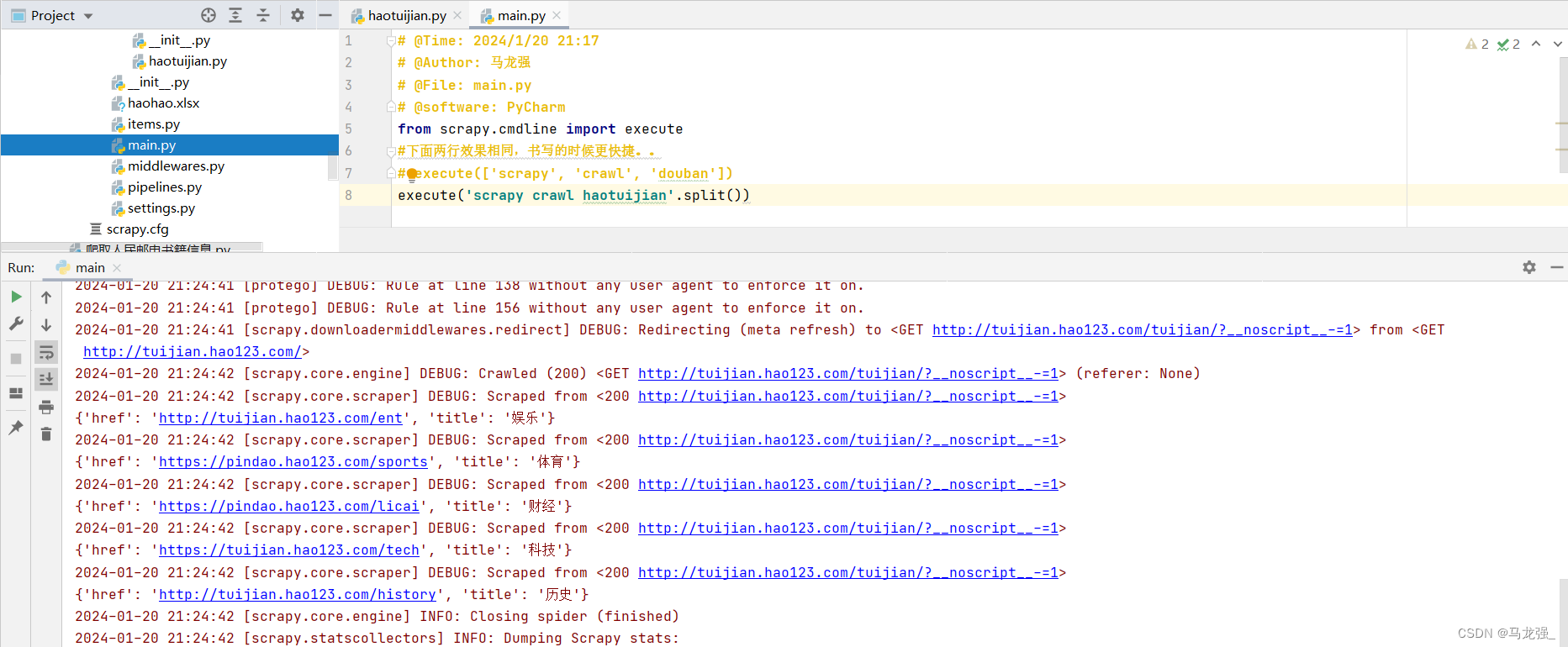
使用Scrapy 爬取“http://tuijian.hao123.com/”网页中左上角“娱乐”、“体育”、“财经”、“科技”、历史等名称和URL
一、网页信息 二、检查网页,找出目标内容 三、根据网页格式写正常爬虫代码 from bs4 import BeautifulSoupimport requestsheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chro