triton专题

【ai】triton-inference-server本地运行
官方地址 下载源码 triton-inference-server/server zhangbin@LAPTOP-Y9KP MINGW64 /x/02_triton_inf_server$ git clone -b r24.05 https://github.com/triton-inference-server/server.gitCloning into 'server'...r
01 Triton backend
1 整体架构 三部分组成: Triton backend tensorRT_backend、onnx_backend、tfs_backend、torch_backend **Triton model ** 不同的模型 **Triton model instance ** 模型实例 
triton之语法学习
一 基本语法 1 torch中tensor的声明 x = torch.tensor([[1,2, 1, 1, 1, 1, 1, 1],[2,2,2,2,2,2,2,2]],device='cuda') 二 triton中函数 1 sum output = tl.sum(x,axis = 0) 如果输入是torch中的声明的话,则输出为 可以看出这个加,并未是一

triton入门实战
这篇文章主要讲的是基于官方镜像及, pytorch script 格式模型,构建tritonserver 服务 1、环境准备: 1.1. 下载 tritonserver镜像: Triton Inference Server | NVIDIA NGC a. 注意:tritonserver 镜像中的invdia驱动版本对应,否则后面会启动失败。 1.2. 然后,拉取Pytorch官方镜像作为推
[python][whl]python模块triton的whl文件下载地址汇总
【windows系列】 triton-2.0.0-cp310-cp310-win_amd64.whl下载地址:https://download.csdn.net/download/FL1623863129/88631360 triton-2.1.0-cp310-cp310-win-amd64.whl下载地址: https://download.csdn.net/download/FL1623
OpenAI Triton 入门教程
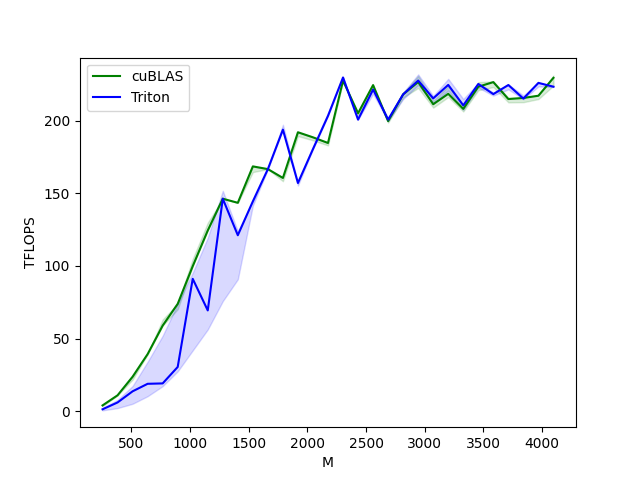
文章目录 Triton 简介背景Triton 与 CUDA 的关系 Triton 开发样例样例一:Triton vector addition 算子Triton kernel 实现kernel 函数封装函数调用性能测试 样例二:融合 Softmax 算子动机Triton kernel 实现kernel 封装单元测试性能测试 样例三:矩阵乘算子 (Matrix Multiplication)动

【BBuf的CUDA笔记】十四,OpenAI Triton入门笔记二
0x0. 前言 接着【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一 继续探索和学习OpenAI Triton。这篇文章来探索使用Triton写LayerNorm/RMSNorm kernel的细节。 之前在 【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现 这篇文章我啃过Apex的LayerNorm实现,整个实现过程是非常复杂的,不仅仅需要

triton inference server翻译之Metrics
link Metrics Triton Inference服务器提供Prometheus度量标准,指示GPU和请求统计信息。 默认情况下,这些指标可从http://localhost:8002/metrics获得。 度量标准仅可通过访问端点来使用,而不会推送或发布到任何远程服务器。 推理服务器的--allow-metrics=false选项可用于禁用度量标准报告,而--metrics-por
triton inference server翻译之Model Repository
link Triton Inference Server访问模型文件的方式可以是本地可访问文件路径,Google Cloud Storage和Amazon S3,用–model-repository选项启动服务器时,将指定这些路径。 对于本地可访问的文件系统,必须指定绝对路径,例如--model-repository=/path/to/model/repository;对于驻留在Google
triton inference server翻译之Quickstart
link Quickstart Triton Inference Server两种获取途径: NVIDIA GPU Cloud (NGC),预编译好的container;GitHub上源码,可用cmake自行编译container; Run Triton Inference Server 运行server $ nvidia-docker run --rm --shm-size=1g -

triton inference server翻译之user guide
link NVIDIA Triton Inference Server提供了针对NVIDIA GPU优化的云推理解决方案。 服务器通过HTTP或GRPC端点提供推理服务,从而允许远程客户端为服务器管理的任何模型请求推理。 对于边缘部署,Triton Server也可以作为带有API的共享库使用,该API允许将服务器的全部功能直接包含在应用程序中。 最新版是1.13.0 更新KFserving

triton inference server翻译之Models And Schedulers
link 通过整合多个框架和自定义后端,Triton Inference Server支持多种模型。 同时,推理服务器还支持多种调度和批处理配置,从而进一步扩展了推理服务器可以处理的模型类别。 本节描述模型的无状态,有状态和组合模式,以及推理服务器如何提供调度程序以支持那些模型类型。 Stateless Models 对于推理服务器的调度程序,无状态模型(或无状态自定义后端)不会维持推理请

triton inference server翻译之Model Configuration
link Model Configuration 模型库中的每个模型都必须包括一个模型配置,该配置提供有关该模型的必需和可选信息。 通常,此配置在指定为ModelConfig protobuf的config.pbtxt文件中提供。 在某些情况下,如生成的模型配置中所述,模型配置可以由推理服务器自动生成,因此不需要显式提供。 最小的模型配置必须指定name, platform, max_bat
triton inference server翻译之Optimization
link Optimization Triton Inference Server具有许多功能,可用于减少模型的延迟和增加吞吐量。 本节讨论了这些功能并演示了如何使用它们来改善模型的性能。 作为先决条件,您应该遵循快速入门,以使服务器和客户端示例与示例模型存储库一起运行。 除非您已经拥有一个适合在推论服务器上测量模型性能的客户端应用程序,否则您应该熟悉perf_client。 perf_cl
triton inference server翻译之model managment
link Model Management 推理服务器以以下三种模型控制模式之一进行操作:NONE,POLL或EXPLICIT。 Model Control Mode NONE 服务器尝试在启动时加载模型存储库中的所有模型。 服务器无法加载的模型在服务器状态中将标记为UNAVAILABLE,并且不可用于推理。 服务器运行时对模型存储库的更改将被忽略。 使用模型控制API的模型控制请求将不
【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一
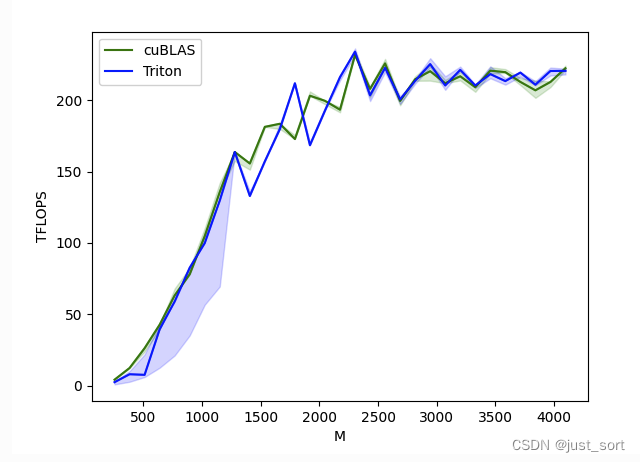
0x0. 前言 2023年很多mlsys工作都是基于Triton来完成或者提供了Triton实现版本,比如现在令人熟知的FlashAttention,大模型推理框架lightllm,diffusion第三方加速库stable-fast等灯,以及很多mlsys的paper也开始使用Triton来实现比如最近刚报道的这个新一代注意力机制Lightning Attention-2:无限序列长度、恒定
triton server报The engine plan file is generated on an incompatible device
错误信息 在启动triton inference server的时候报 I0701 02:42:42.028366 1 cuda_memory_manager.cc:103] CUDA memory pool is created on device 0 with size 67108864I0701 02:42:42.031240 1 model_repository_manager.cc
triton server报The engine plan file is generated on an incompatible device
错误信息 在启动triton inference server的时候报 I0701 02:42:42.028366 1 cuda_memory_manager.cc:103] CUDA memory pool is created on device 0 with size 67108864I0701 02:42:42.031240 1 model_repository_manager.cc
Triton + HF + Qwen 推理经验总结
1. 简介 Triton介绍参考:GitHub - triton-inference-server/tutorials: This repository contains tutorials and examples for Triton Inference Server 2. 实现方案 2.1. docker部署 # 拉取docker镜像git clone -b r23.10 http