tokentm专题
揭秘视觉Transformer之谜,TokenTM新法,全面提升模型解释性能
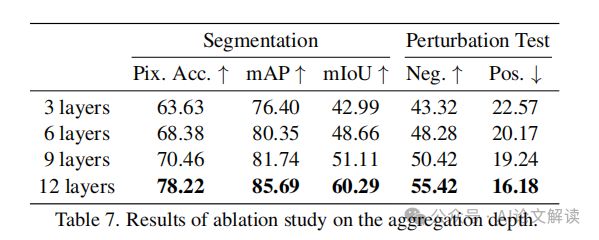
引言:揭示视觉Transformer的解释挑战 在计算机视觉应用中,Transformer模型的流行度迅速上升,但对其内部机制的后置解释仍然是一个未探索的领域。视觉Transformers通过将图像区域表示为转换后的tokens,并通过注意力权重将它们整合起来来提取视觉信息。然而,现有的后置解释方法仅考虑这些注意力权重,忽略了转换tokens中的关键信息,这无法准确地展示模型预测背后的逻辑