tokenization专题
tokenization(二)子词切分方法
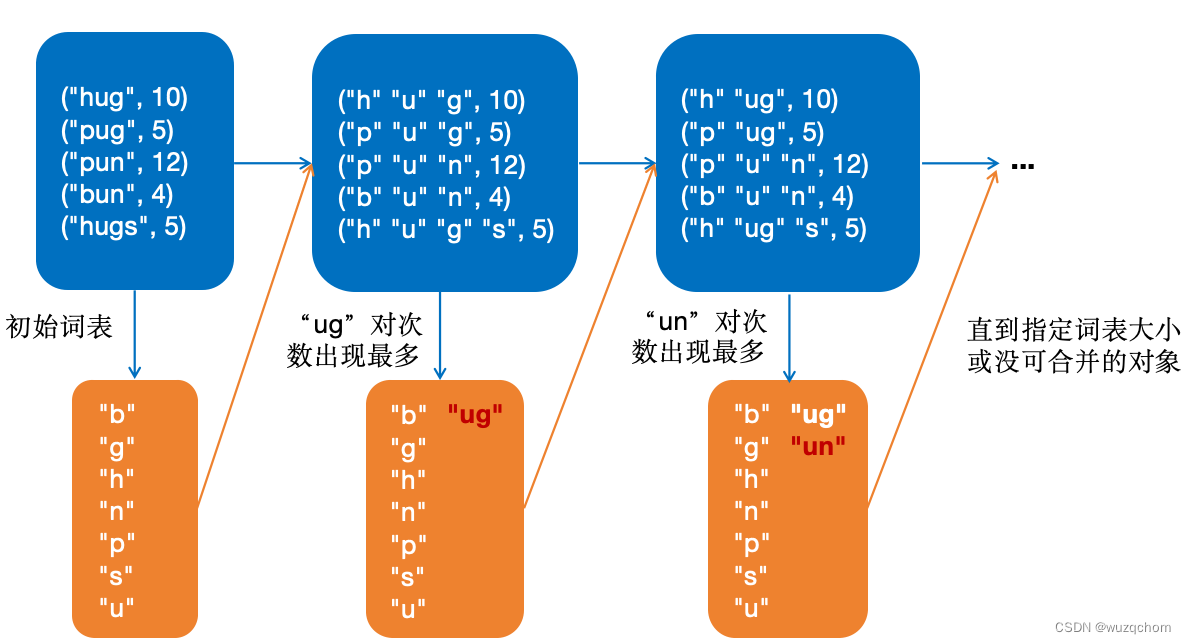
文章目录 概述BPE构建词表词元化代码实现 WordPieceUnigram估算概率(E)删除词元(M) 参考资料 概述 接上回,子词词元化(Subwords tokenization)是平衡字符级别和词级别的一种方法,也是目前用得最多的方法。 子词词元化的目标有2个: ● 常见词不应该切分为更小的单元 ● 罕见词应该被分解为有意义的子词 BPE BPE(Byte-Pair

bert源码分析之tokenization
import collections# 集合模块 import re# 正则模块 import unicodedata#判断字符类别模块 import six#判断版本 import tensorflow as tf # 用于检查传入的参数do_lower_case和真正的模型是否一致 # do_lower_case: 一个布尔值,表示是否将文本转换为小写 # init_checkpoint: 初

Token、Tokenization 和张量之间的关系
输入经过Tokenization、Embedding和Positional Encoding后,最终构建为张量,给后续的计算和处理带来很多优势。 1. tokenization和张量 在自然语言处理(NLP)领域中,tokenization 是文本预处理的重要步骤之一,它是指将一段连续的文本分割成离散的单元,这些单元通常被称为tokens。Tokens可以是单个词、字符、子词

GPT-4模型中的token和Tokenization概念介绍
Token从字面意思上看是游戏代币,用在深度学习中的自然语言处理领域中时,代表着输入文字序列的“代币化”。那么海量语料中的文字序列,就可以转化为海量的代币,用来训练我们的模型。这样我们就能够理解“用于GPT-4训练的token数量大约为13万亿个”这句话的意思了。代币越多,训练次数越多,最终模型的质量一般也越好。13万亿个,这个数目是指在模型训练过程中所使用的数据集中的总token数

从NLP中的标记算法(tokenization)到bert中的WordPiece
文章目录 词级标记 (Word level tokenization)字符级标记 (Character level tokenization)子字级标记 (Subword level tokenization)WordPiece 子字级标记算法BPE(Basic Periodontal Examination) 所谓 tokenization ,就是如何提取或者说是记录文本中词语,常
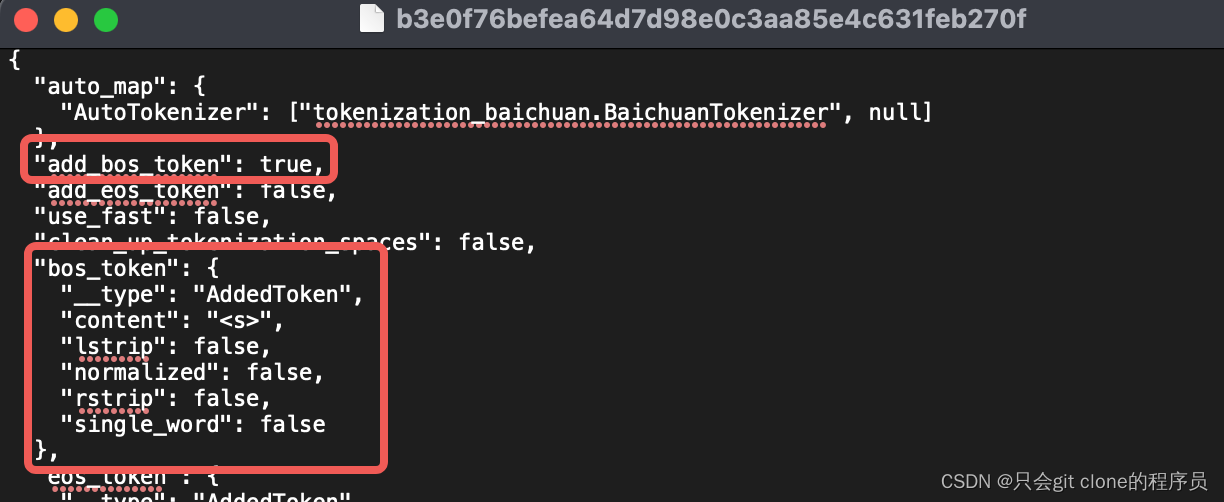
WARNING: tokenization mismatch: 403 vs. 406. (ignored) LLaVa
LLaVa换BaiChuan底座报错 WARNING: tokenization mismatch: 403 vs. 406. (ignored) 解决 cd ~/.cache/huggingface/hub/models--baichuan-inc--Baichuan2-7B-Base/snapshots/0cc6a61c06cd0734270151109d07cf86ef0ace53v