tcmalloc专题
顺便测试了一下google的tcmalloc.
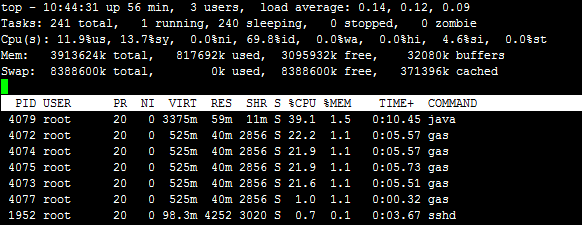
还是原来那台机器, 做了这样几个改动: 1. 将工作线程减少到和CPU个数一样, 也就是4个. 2. 将测试客户端代码放在测试机上运行, 通过127.0.0.1来通信, 以减少网络抖动带来的差异. 3. 将消息量提高到 28000条/s. 测试结果如下: a). 链接上tcmalloc. 结果: b). 不链接tcmalloc 结果.
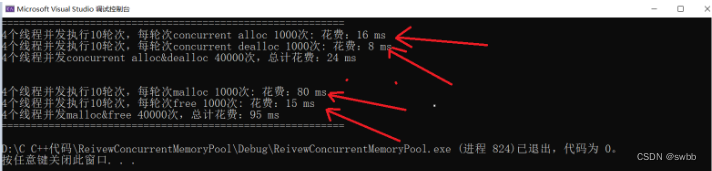
tiny-Tcmalloc(高并发内存池)
项目地址(绝对可运行) 一. 初识高并发内存池 1、项目介绍 当前项目是实现一个高并发的内存池,它的原型是google的一个开源项目tcmalloc,tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc 、free)。 2、项目所需的知识 C/C++、数据结构(链表、哈希桶)、

go语言内存分配之TCMalloc
tcmalloc tcmalloc 优点 速度更快,比glicbc 2.3 快占用更少的内存空间,8倍8-byte的对象内存分配中占用大约8N*1.01byte的头空间,而ptmalloc则会占用16N*byte的头空间 使用 在程序中只需使用“-ltmalloc”连接标识将其链接到程序中 综述 TCMalloc为每一个线程分配本地缓存,以满足小对象分配的需求,当需要时候,对象从中央数

【项目实战】高并发内存池(仿tcmalloc)
【项目实战】高并发内存池(仿tcmalloc) 作者:爱写代码的刚子 时间:2024.2.12 前言: 当前项目是实现一个高并发的内存池,它的原型是google的一个开源项目tcmalloc,tcmalloc全称 Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free)。这个项目是把tcmall

使用tcmalloc提升mysql性能
http://www.china-lg.com/blog/index.php?play=reply&id=537 网上搜到了tcmalloc,说是这个东西可以让MySQL在高并发下性能也很稳定,同时也说了MySQL这个问题是因为malloc内存分配函数的bug,这个bug会使高并发的MySQL性能急剧下降。 使用google的tcmalloc 内存分配函数代替libc里的标准malloc.

测试内存分配器:ptmalloc2 vs tcmalloc vs hoard vs jemalloc,同时尝试模拟真实世界的负载
原文 当我们为参与者开发自己的分配器时,我们需要对其进行测试,更重要的是,需要将其与现有的分配器进行基准测试。显然,虽然有相当多的分配器测试程序,但这些测试中的大多数并不能代表真实世界的负载,因此,只能提供关于真实程序中分配器性能的非常粗略的想法。 例如,相当流行的t-test1.c(参见,例如,t-test1.c)经常被用作单元测试,因此它必须测试诸如calloc()和 realloc() 之
【项目设计】高并发内存池—tcmalloc核心框架学习
目录 一、项目介绍 二、内存池的初步认识 2.1 池化技术 2.2 内存池 2.3 malloc 三、定长内存池 四、整体框架设计介绍 五、申请内存 5.1 ThreadCache 5.1.1 ThreadCache整体设计 5.1.2 ThreadCache哈希桶映射与对齐规则 5.1.3 TSL无锁访问 5.1.4 ThreadCache核心设计 5.2 Centr
google tcmalloc WIN下使用
所用版本为: google-perftools-1.6 a.) 作为动态链接库时: 不用改变任何设置,编译即可。 使用时,工程设置如下: 1.运行时库改为 mdd/md 2.附加依赖库 libtcmalloc_minimal.lib 3.强制符号引用 __tcmalloc 这样就可以正确的使用tcmalloc库了(dll
【tcmalloc】优化方法
一.脱离new使用定长内存池 此项目本意是脱离malloc的使用,但若使用new的话仍然会使用到malloc。因为centralcache和pagecache本身是单例,不考虑创建对象的问题,但是每个线程自身拥有个线程缓冲区和span结构是要考虑new的问题的,引入定长内存池替换new可一提高效率。 二.释放内存的时候不传入对象大小 我们在释放的时候可以拿到内存块的真实物理地址,我们可以通过
【tcmalloc】(二)整体设计和thread cache(申请)
一.高并发内存池整体框架设计 内存池需要考虑以下几方面的问题。 1. 性能问题。 2. 多线程环境下,锁竞争问题。 3. 内存碎片问题(外碎片(内存不连续无法使用),内碎片(因为对齐规则的浪费)) malloc 一进入多线程就加锁,tcmalloc有可能不用加锁。 1.thread cache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内 存不需要加锁,每个
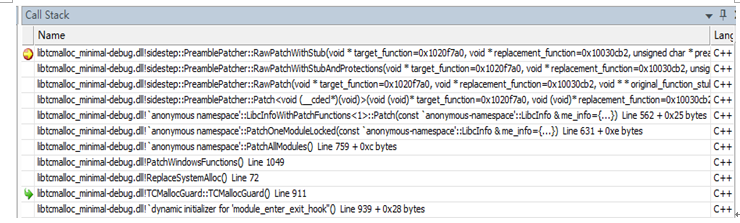
原 深入了解tcmalloc(一):windows环境下无缝拦截技术初探
http://my.oschina.net/u/877348/blog/272066 概述: 又到了一个总结提炼的阶段,这次想具体聊聊游戏引擎中使用的内存管理模块tcmalloc组件的使用心得。项目的前期曾经遇到过内存瓶颈,特别是windows系统下的客户端程序在经历长时间运行之后会出现内存占用率很高疑似泄漏的现象,排查了很久都没有找到原因,甚至一度无法定位问题出自游

training become slow?训练速度奇怪的变慢?tcmalloc在tensorflow中的使用!
--------------------前言------------------------ 在训练视频分类训练的时候,发现tensorflow莫名的变慢2~5 sec /batch, 之前一直是0.4 sec/batch, 联想到最早之前mxnet训练分类时候的类似情况,决定做排查(都是同一台训练服务器上): (1)杀掉一些僵尸进程或多并行进程,eg. im2rec, 发现不见效,并且cpu
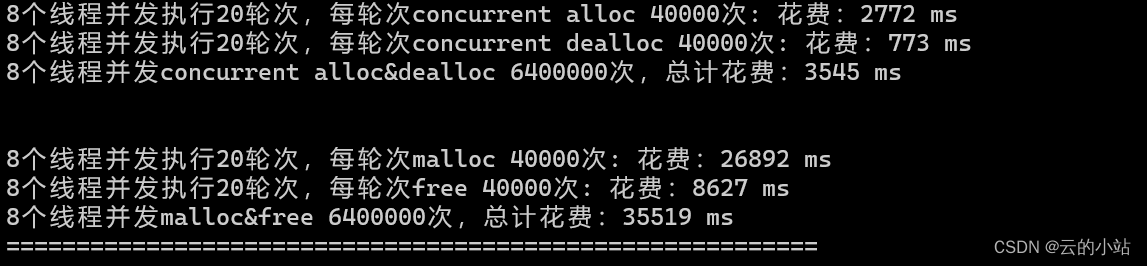
tcmalloc 框架介绍
tcmalloc解决锁频繁加锁解锁以及缓解锁竞争问题,尤其是在多线程并发申请内存的时候,相比malloc效率大大提升。 20轮,每次8个线程,每次个线程申请10000次,释放10000次; malloc和我们的tcmalloc相比,malloc像个万金油,哪里都能有,但是哪里都不突出,所以在多线程高并发申请内存的过程中相比tcmalloc,malloc内存池申请是缓慢的。所以,我们创造tcma