synthetic专题

论文阅读1 Scaling Synthetic Data Creation with 1,000,000,000 Personas
Scaling Synthetic Data Creation with 1,000,000,000 Personas 链接:https://github.com/tencent-ailab/persona-hub/ 文章目录 Scaling Synthetic Data Creation with 1,000,000,000 Personas1. 摘要2. 背景2.1 什么是数据合成2

Synthetic Data for Text Localisation in Natural Images(人工合成带有文本的图片)
https://github.com/JarveeLee/SynthText_Chinese_version 1.解决python3的pickle.load错误:a bytes-like object is required, not 'str' 经过几番查找,发现是Python3和Python2的字符串兼容问题,因为数据文件是在Python2下序列化的,所以使用Python3读取时,需要将‘
Java Synthetic Method
参考链接:https://www.oschina.net/code/snippet_2438265_54869 The Java Language Specification (section 13.1)Java语言规范13章写道 :由编译器产生的任何构建,如果在源码中没有对应的构建存在,那么这个构建就必须被标记为synthetic(除了默认构造器和类初始化方法。)原话如下: “Any

AtCoder Beginner Contest 119 C - Synthetic Kadomatsu
AtCoder Beginner Contest 119 C - Synthetic Kadomatsu ABC 119 https://atcoder.jp/contests/abc119/tasks 最近感觉AtCoder挺喜爱的,就是题解几乎都是日文的,找不到英文的,有点难受,谷歌翻译又有点蛋疼,难道我应该学日语吗? 日本人的博客还可以,借助谷歌翻译和代码管中窥豹也能学到一些东西,这题一

Synthetic Temporal Anomaly Guided End-to-End Video Anomaly Detection 论文阅读
Synthetic Temporal Anomaly Guided End-to-End Video Anomaly Detection 论文阅读 Abstract1. Introduction2. Related Work3. Methodology3.1. Architecture3.1.1 Autoencoder3.1.2 Temporal Pseudo Anomaly Synthes

ICML23 - Synthetic Data for Model Selection
前言 如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 本文关注的问题为:是否可以使用合成数据(Synthetic Data)用于模型选择?即不再划分验证集,而是将所有标记数据作为训练集,使用训练集生成的合成数据来挑选模型。 本文中关注的「模型选择」,是指根据训练集训练得到的多个模型(不同网络架构,不同超参等)的选择。

论文笔记-Learning from Synthetic Data for Crowd Counting in the Wild 人群计数新方法
Hello, 今天是论文阅读计划的第11天啦。 今天介绍的这篇论文是CVPR 2019的一篇论文,是关于在室外拥挤的人群中的人群计数问题。哈哈,这是我在看别人整理的CVPR论文合集的时候,发现了这篇论文,然后对这个任务有点好奇,所以就下载来看看学习下了。 附上别人整理资料: CVPR 2020 论文开源项目合集:https://github.com/amusi/CVPR2020-Code E
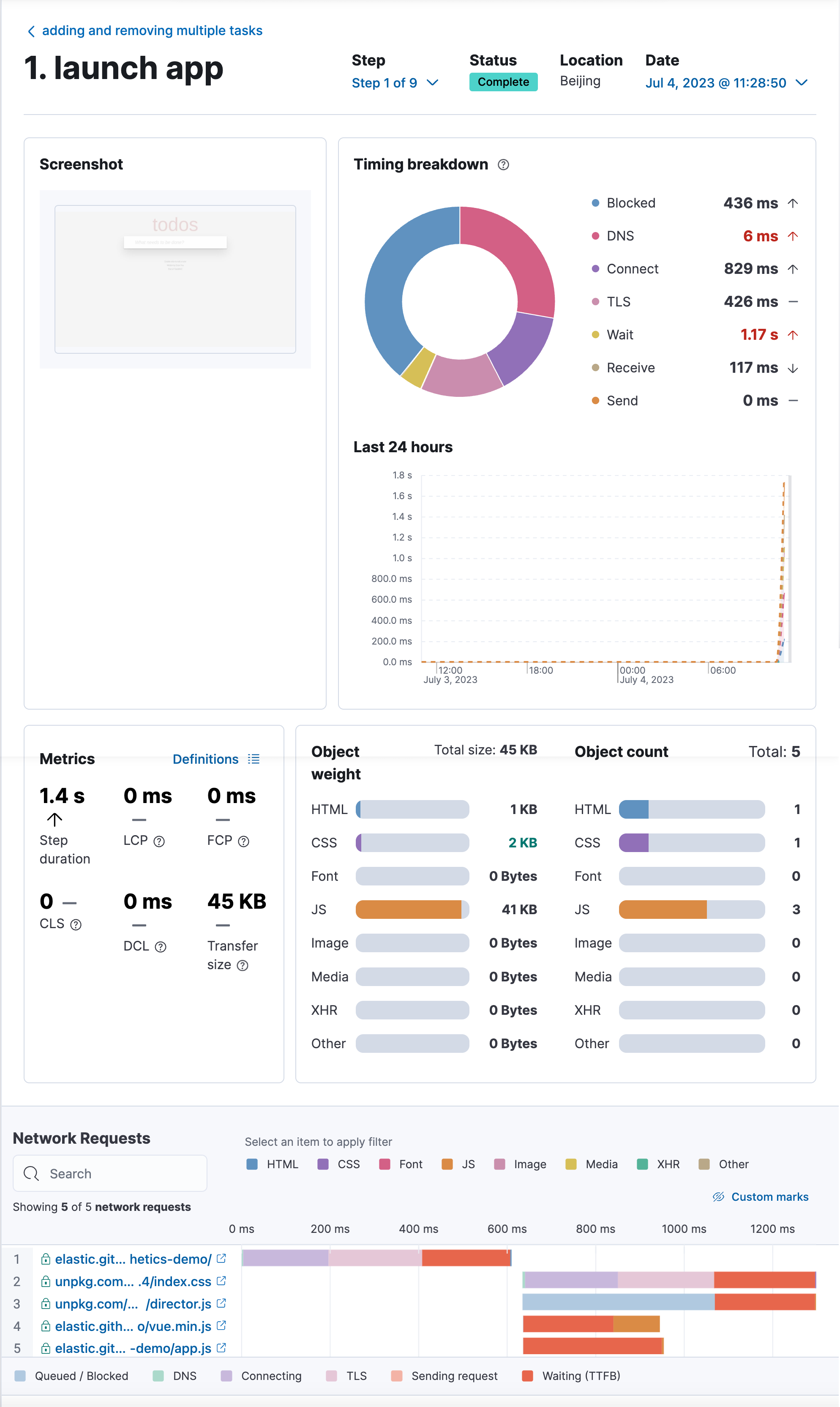
Observability:Synthetic monitoring - 合成监测入门(一)
从我们的全球测试基础设施监控关键用户旅程,并了解网络和前端性能对用户体验的影响。 全面了解你的网站性能、功能和可用性(从开发到生产),并在客户之前发现问题。合成监测(synthetic monitoring)使你能够模拟、跟踪和可视化关键用户旅程的性能。本文将从零基础教会你如何对网站进行检测。合成监测扩展了传统的端到端测试技术,因为它允许你的测试在云上持续运行。 通过综合监测,你可以通过重复使用用

【深度学习:Synthetic Training Data 】合成训练数据简介
【深度学习:Synthetic Training Data 】合成训练数据简介 什么是合成训练数据?创建合成数据的两种方法 尽管文明正在产生大量的数据(根据最近的研究,每天有 2.5 万亿字节的新数据),但计算机视觉和机器学习数据科学家在获取足够的数据来训练和制作计算机视觉模型时仍然面临许多挑战。 算法生成的模型需要对大量数据进行训练,但有时这些数据并不容易获得。 设计高

Validating Seed Data Samples for Synthetic Identities – Methodology and Uniqueness Metrics论文笔记
验证种子数据样本的合成身份-方法学和唯一性度量 摘要:探索了GAN合成人脸的身份唯一性。目标是判断身份唯一性,分别针对用于训练GAN的种子数据集和合成人脸样本。使用了两种方法分别是ROC曲线和阈值技术。使用了真实人脸的公开数据集样本作为ROCs的参考基准。 1.介绍 动机:合成大规模人脸数据集,第一步确定身份的唯一性,随后构建关注其他面部属性(光照,姿势和表情) 研究问题: 1)对比用于训