strom专题

strom架构和构建Topology
1.Hadoop的MapReduce与Storm的topology有什么不一样的地方? 2.Nimbus与hadoop的jobtracer作用是否类似? 3.Nimbus和Supervisor之间的所有协调工作有谁来完成? 4.一个topology由哪两部分组成? 5.Storm HA模式如果机器意外停止,是如何处理任务的? 6.storm如何运行一个topology 7.Spout类里面最重要的

JStorm和Strom的区别,没有对比就没有伤害
前言 Storm的内核是clojure编写的,目前阿里巴巴公司已经有开源的Copy版本JStorm。 简单的概述对比就是: JStorm 比Storm更稳定,更强大,更快,Storm上跑的程序,一行代码不变可以运行在JStorm上。直白的将JStorm是阿里巴巴的团队基于Storm 的二次开发产物,相当于他们的Tengine是基于Nginx开发的一样。 以下为阿里巴巴团队放弃直接使用Stor
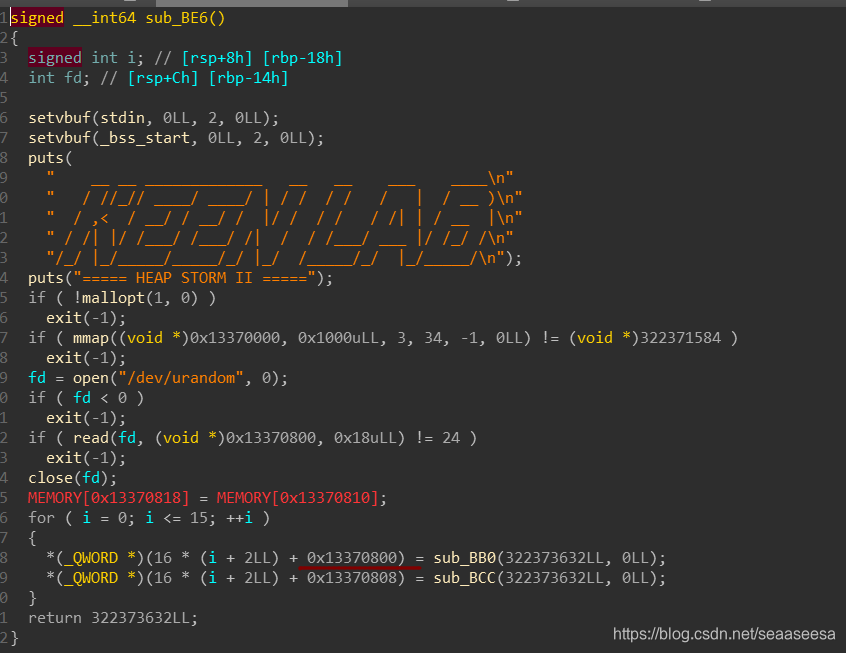
large bin attack house of strom
large bin attack & house of strom large bin attack是一种堆利用手法,而house of strom则是在large bin attack的基础上借用unsorted bin来达到任意地址分配,首先我们从源码入手来分析large bin attack原理,然后再讲讲house of strom的原理,接着再看几个题目。 为例方便分析,以2.23为
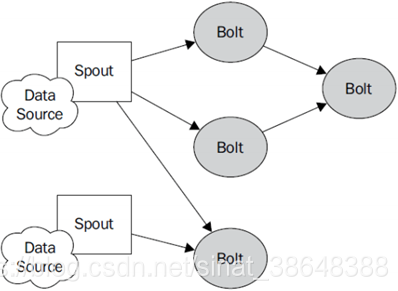
Strom核心组件与编程模型
1.Strom介绍 Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。提供简单容易理解的接口,便于开发 2.strom与hadoop的区别 Storm用于实时计算,Hadoop用于离线计算。 Storm处理的数据保存在内存中,源源不断;Hadoop处理的数据保存在文件系统中,一批一批。 Storm的数据通过网络传输进来;Hadoop的数据保存在磁盘中。

Strom最火的流式处理
实现一个实时计算系统 全量数据处理使用的大多是鼎鼎大名的hadoop或者hive,作为一个批处理系统,hadoop以其吞吐量大、自动容错等优点,在海量数据处理上得到了广泛的使用。但是,hadoop不擅长实时计算,因为它天然就是为批处理而生的,这也是业界一致的共识。否则最近这两年也不会有s4,storm,puma这些实时计算系统如雨后春笋般冒出来啦。先抛开s4,storm,puma这些系统不谈,