streamingt2v专题
StreamingT2V文本生成视频多模态大模型,即将开源!
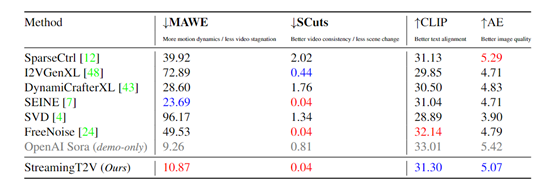
1、前言 Picsart人工智能研究所、德克萨斯大学和SHI实验室的研究人员联合推出了StreamingT2V视频模型。通过文本就能直接生成2分钟、1分钟等不同时间,动作一致、连贯、没有卡顿的高质量视频。 虽然StreamingT2V在视频质量、多元化等还无法与Sora媲美,但在高速运动方面非常优秀,这为开发长视频模型提供了技术思路。 研究人员表示,理论上,Streaming

两分钟1200帧的长视频生成器StreamingT2V来了,代码将开源
两分钟1200帧的长视频生成器StreamingT2V来了,代码将开源 广阔的战场,风暴兵在奔跑…… prompt:Wide shot of battlefield, stormtroopers running… 这段长达 1200 帧的 2 分钟视频来自一个文生视频(text-to-video)模型,尽管 AI 生成的痕迹依然浓重,但我们必须承认,其中的人物和场景具有相当不错的一致性。