spark3.3专题

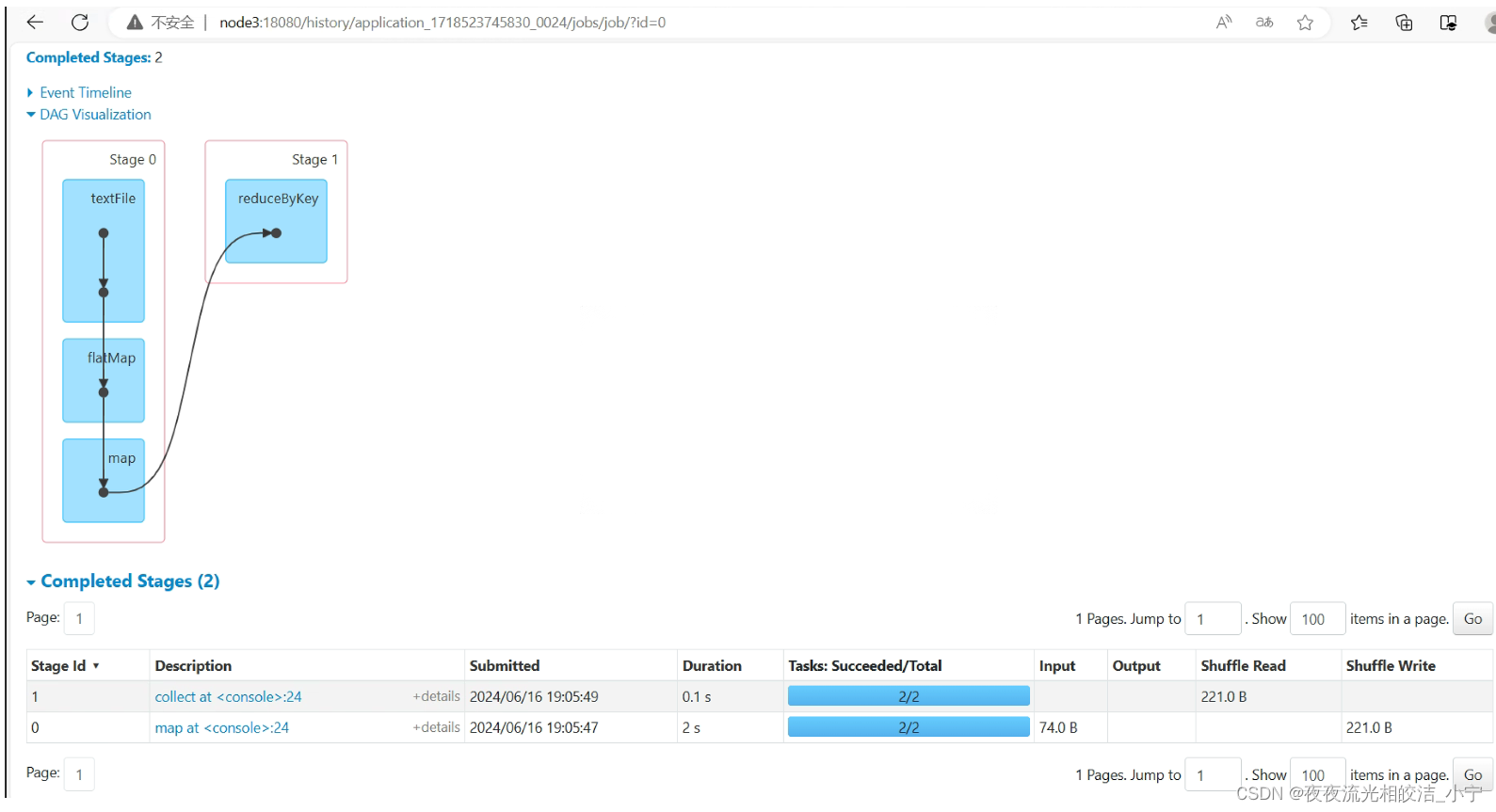
基于Spark3.3.4版本,实现Standalone 模式高可用集群部署
目录 一、环境描述 二、部署Spark 节点 2.1 下载资源包 2.2 解压 2.3 配置 2.3.1 配置环境变量 2.3.2 修改workers配置文件 2.3.3 修改spark.env.sh文件 2.3.4 修改spark-defaults.conf 2.4 分发 2.5 启动服务 2.5.1 启动zookeeper 2.5.2 启动hdfs 2.5.
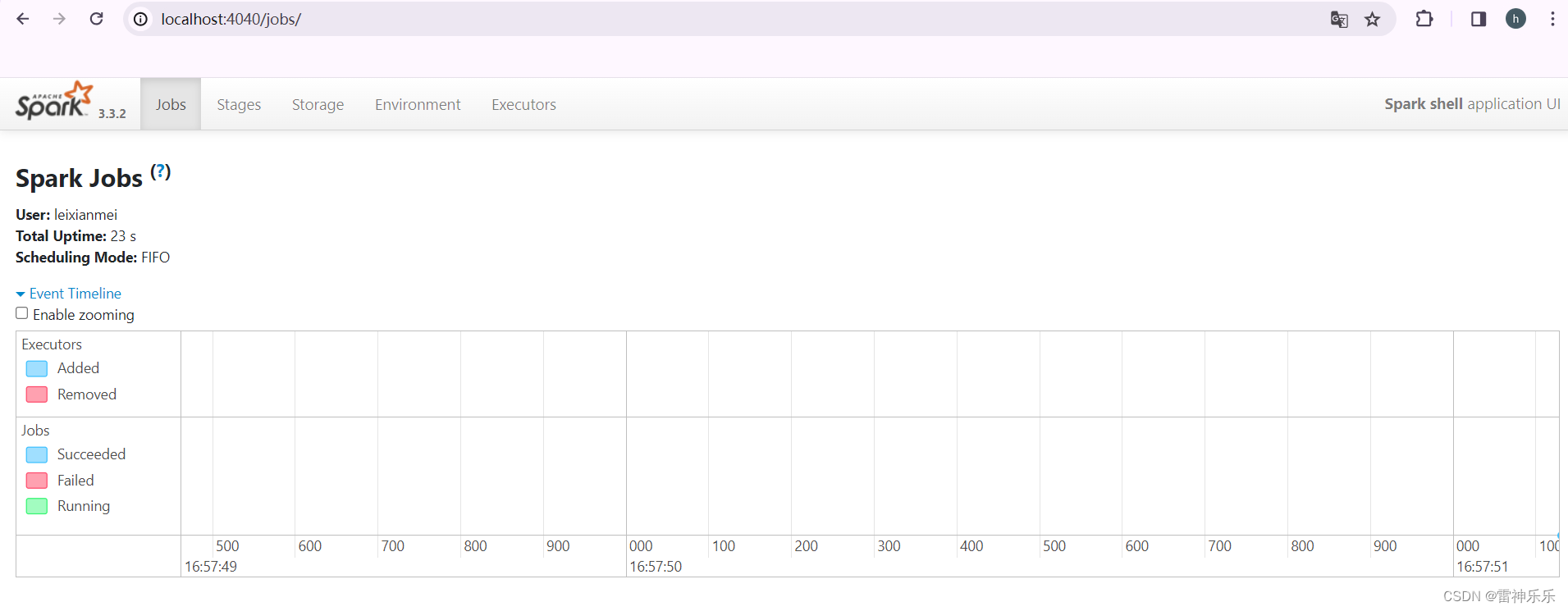
基于Spark3.3.4版本,实现Spark On Yarn 模式部署
目录 一、环境描述 二、部署Spark 节点 2.1 下载资源包 2.2 解压 2.3 配置 2.3.1 配置hadoop信息 2.3.1.1 修改yarn-site.xml 2.3.1.2 mapred-site.xml 2.3.2 配置spark-env.sh 2.3.3 配置spark-defaults.conf 2.4 分发 2.5 启动服务 2.5.1
Windows环境部署Hadoop-3.3.2和Spark3.3.2
目录 一、Windows环境部署Hadoop-3.3.2 1.CMD管理员解压Hadoop压缩包 2.配置系统环境变量 3.下载hadoop winutils文件 4.修改D:\server\hadoop-3.3.2\etc\hadoop目录下的配置文件 (1)core-site.xml (2)hdfs-site.xml (3)mapred-site.xml (4)yarn-si
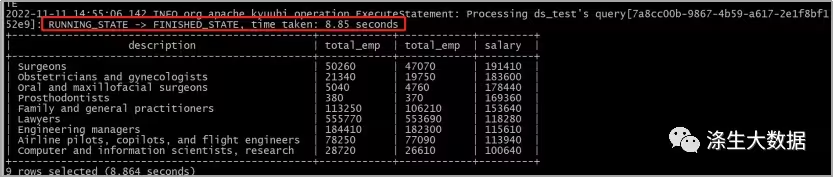
大数据平台实践之CDH6.2.1+spark3.3.0+kyuubi-1.6.0
前言:关于kyuubi的原理和功能这里不做详细的介绍,感兴趣的同学可以直通官网:https://kyuubi.readthedocs.io/en/v1.7.1-rc0/index.html 下载软件版本 wget http://distfiles.macports.org/scala2.12/scala-2.12.16.tgzwget https://archive.apach