snappy专题

MongoDB~俩大特点管道聚合和数据压缩(snappy)
场景 在MySQL中,通常会涉及多个表的一些操作,MongoDB也类似,有时需要将多个文档甚至是多个集合汇总到一起计算分析(比如求和、取最大值)并返回计算后的结果,这个过程被称为 聚合操作 。 根据官方文档介绍,我们可以使用聚合操作来: 将来自多个文档的值组合在一起。对集合中的数据进行的一系列运算。分析数据随时间的变化。 聚合 MongoDB 提供了两种执行聚合的方法: 聚合管道(Agg

barryvdh/laravel-snappy网页转图片、pdf
一、下载wkhtmltopdf 下载地址:https://wkhtmltopdf.org/downloads.html 选择对应的版本下载(我的homestead是ubuntu的16.04.3下载的是Ubuntu 16.04(xenial) amd64) 解压wkhtmltox_0.12.5-1.xenial_amd64.deb,将其中的usr文件单独拿出来放到根目录 二、安装barryvdh

hadoop 压缩-snappy
下载安装Apache hadoop-1.2.1(bin.tar.gz文件)搭建集群后,在运行wordcount 时报警告 WARN snappy.LoadSnappy: Snappy native library not loaded。 我们想要给Hadoop集群增加snappy压缩支持。很多发行版的hadoop已经内置了snappy/lzo压缩,比如cloudera CDH, Hortonw
最笨的方法解决 使用Snappy 压缩方式报错“java.lang.UnsatisfiedLinkError: no snappyjava in java.library.path”
之前写过一篇这个文章:http://blog.csdn.net/stark_summer/article/details/47361603,那个时候 linux环境 spark 使用snappy方式压缩任然不好用,而今天我同事hive on hadoop 使用snappy压缩方式也报这个错,此刻的我,感觉这个问题 一定要解决 我想了想,只能使用最笨的方式先解决这个问题了,将libsnappyja

Hive数仓建表时选用ORC还是PARQUET,压缩选Lzo还是snappy?
目录 1 文件存储格式1.1 ORC1.1.1 ORC的存储结构1.1.2 关于ORC的hive配置 1.2 Parquet1.2.1 Parquet的存储结构1.2.2 Parquet的表配置属性 1.3 ORC和Parquet对比 2 压缩方式3 存储和压缩结合该如何选择?3.1 ORC格式存储,Snappy压缩3.2 Parquet格式存储,Lzo压缩3.3 Parquet格式存储,S

Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
因为上一篇文章中提到我在数仓的ods层因为使用的是 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'存储模式,但是遇到了count(*) 统计结果与select
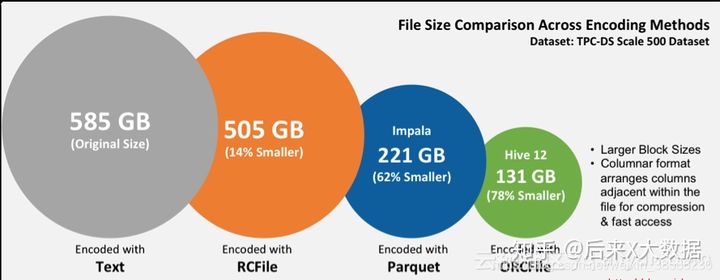
Hive数仓中存储格式ORC和Parquet,压缩方式LZO和Snappy
自我总结: LZO支持切片,Snappy不支持切片。 ORC和Parquet都是列式存储。 ORC和Parquet 两种存储格式都是不能直接读取的,一般与压缩一起使用,可大大节省磁盘空间。 选择:ORC文件支持Snappy压缩,但不支持lzo压缩,所以在实际生产中,使用Parquet存储 + lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数
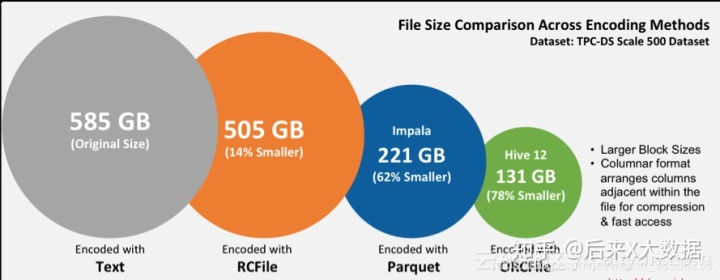
hive 修改cluster by算法_Hive数仓建表该选用ORC还是Parquet,压缩选LZO还是Snappy?
欢迎大家微信搜索:后来X大数据,更多精彩文章都会在公众号准时更新。 大家好,我是后来,周末理个发,赶脚人都精神了不少,哈哈。 因为上一篇文章中提到我在数仓的ods层因为使用的是 STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.h