simulators专题
学习Sora技术报告Video generation models as world simulators
原文链接: Video generation models as world simulators (openai.com) 摘要: 我们探索了在视频数据上大规模训练生成模型。具体来说,我们在可变片长、分辨率和纵横比的视频和图像上联合训练文本条件扩散模型text-conditional diffusion models。我们利用一种 transformer 架构,该架构在视频和图像潜在代码的时

Video generation models as world simulators-视频生成模型作为世界模拟器
原文地址:Video generation models as world simulators 我们探索在视频数据上进行大规模生成模型的训练。具体来说,我们联合训练文本条件扩散模型,同时处理不同持续时间、分辨率和长宽比的视频和图像。我们利用一个在视频和图像潜在编码的时空块上运行的转换器结构。我们最大的模型Sora能够生成一分钟高保真度视频。我们的结果表明,扩展视频生成模型是建立物理世界通用目的

Sora技术报告——Video generation models as world simulators
文章目录 1. 视频生成模型,可以视为一个世界模拟器2. 技术内容2.1 将可视数据转换成patches2.2 视频压缩网络2.3 Spacetime Latent Patches2.4 Scaling transformers 用于视频生成2.5 可变的持续时间,分辨率,宽高比2.6 抽样的灵活性2.7 改进框架和构图2.8 为视频生成字幕,作为训练集 3. 应用3.1 动画DALL·E图
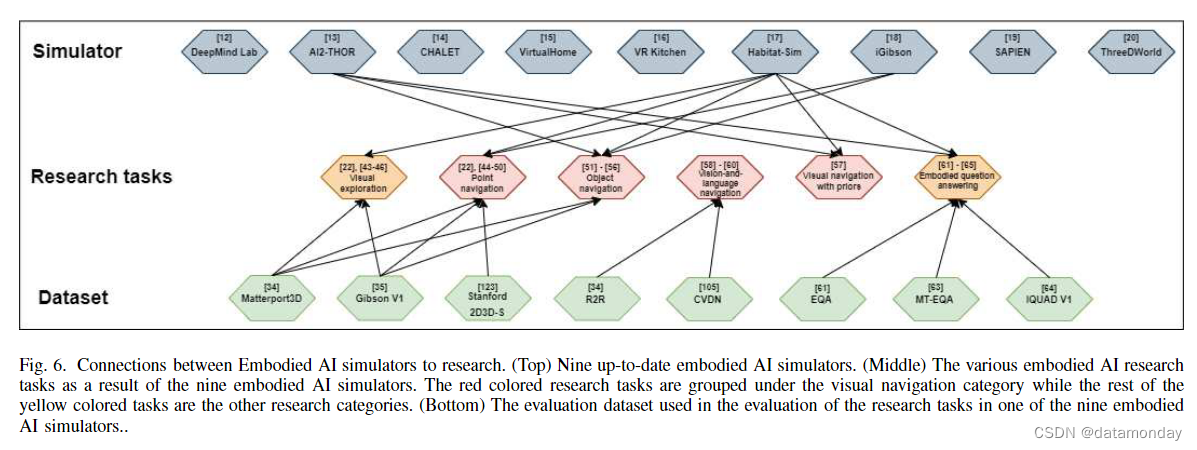
【具身智能综述1】A Survey of Embodied AI: From Simulators to Research Tasks
论文标题:A Survey of Embodied AI: From Simulators to Research Tasks 论文作者:Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, Cheston Tan 论文原文:https://arxiv.org/abs/2103.04918 论文出处:IEEE Transactions on Emer

论文阅读:A Survey of Embodied AI: From Simulators toResearch Tasks
介绍 具身智能可粗略定义为,智能体(可以是生物或机械),通过与环境产生交互后,通过自身的学习,产生对于客观世界的理解和改造能力。具身智能假设,智能行为可以被具有对应形态的智能体通过适应环境的方式学习到。因此,地球上所有的生物,都可以说是具身智能。 但就目前而言,具身智能是将视觉、语言和推理等传统智能概念融入人工智能体中,以帮助解决虚拟环境中的人工智能问题。 具身智能模拟器 具身智能模