simplified专题
MapReduce Simplified Data Processing on Large Clusters 论文笔记
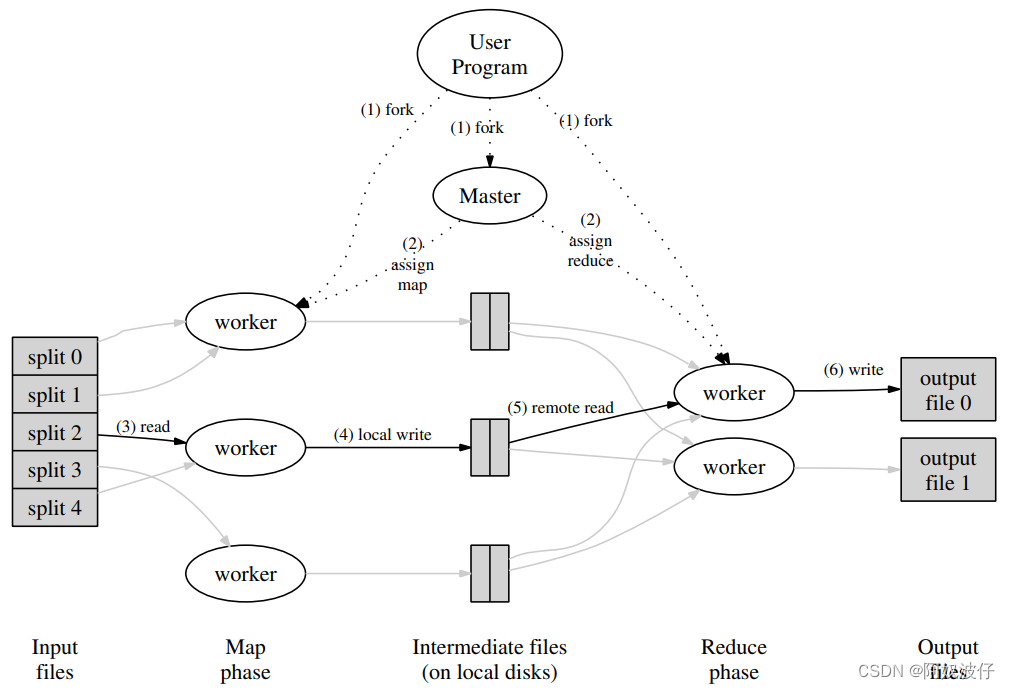
2003年USENIX,出自谷歌,开启分布式大数据时代的三篇论文之一,作者是 Jeffrey 和 Sanjay,两位谷歌巨头。 Abstract MapReduce 是一种变成模型,用于处理和生成大规模数据。用户指定 map 函数处理每一个 key/value 对来产生中间结果的 key/value 对;reduce 函数合并每一个相同中间 key 的 value。 这种编程风格能自动获得并

Home Network Security Simplified
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp A straightforward, graphic-based reference book for network security for the home and small business *A

【课程论文阅读】MapReduce: Simplified Data Processing on Large Clusters
文章目录 paper 中文翻译 MapReduce 论文阅读—不错的博客 该博主其他文章: 6.824 分布式系统课程学习总结
【课程论文阅读】MapReduce: Simplified Data Processing on Large Clusters
文章目录 paper 中文翻译 MapReduce 论文阅读—不错的博客 该博主其他文章: 6.824 分布式系统课程学习总结

QT trimmed和simplified
trimmed:去除了字符串开头前和结尾后的空白; simplified:去除了字符串开头前和结尾后的空白,以及中间内部的空白字符也去掉(\t','\n','\v','\f','\r'和' ') 代码: QString str = " 1 2 3 4 5 \t \n ABCDE ";str = str.trimmed();qDebug() << "start:"
QT trimmed和simplified
trimmed:去除了字符串开头前和结尾后的空白; simplified:去除了字符串开头前和结尾后的空白,以及中间内部的空白字符也去掉(\t','\n','\v','\f','\r'和' ') 代码: QString str = " 1 2 3 4 5 \t \n ABCDE ";str = str.trimmed();qDebug() << "start:"

对于MapReduce: Simplified Data Processing on Large Clusters 的理解
MapReduce: Simplified Data Processing on Large Clusters这个论文原版的没看,找了几个网上流传的翻译稿,认真看了一遍。因为内容主要为大数据方面,目前自己还没直接接触到这方面的内容,先记录一下收获,不然用到的时候都忘光了(见笑了。。) 先记录一下翻译比较好的文章,我自己看着逻辑上没啥大毛病的翻译稿(个人水平有限,别吐槽,见谅。。。): 第一个是

AtCoder Beginner Contest 179 F.Simplified Reversi
AtCoder Beginner Contest 179 F.Simplified Reversi 题目链接 非常有趣的思维题~ 假设黑色区域宽为 x x x,长为 y y y,我们考虑一种修改,比如 1 , k 1,k 1,k,此时不难发现修改后对 [ k + 1 , y ] [k+1,y] [k+1,y] 的 1 1 1 操作,都是固定的减去 x x x,所以这是一种典型的缩
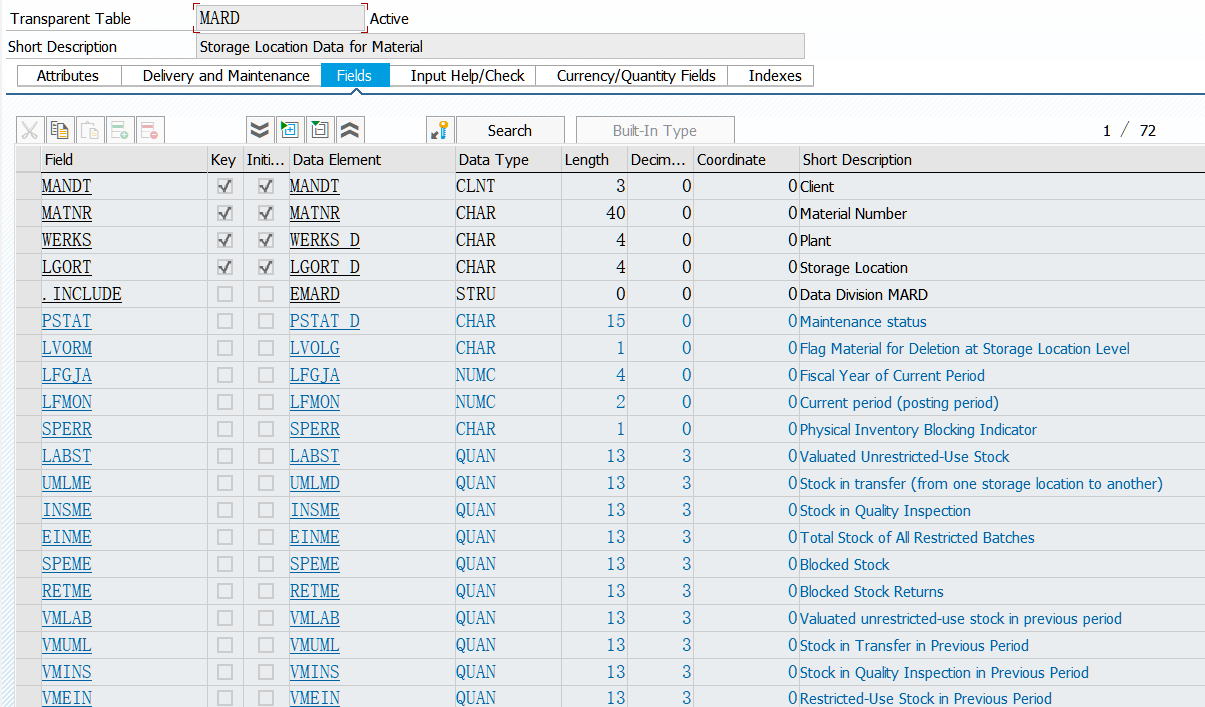
SAP S/4HANA New Simplified Data Model (NSDM) 模型介绍
SAP ERP Central Component(简称 ECC)库存管理数据模型,是建立在物料文档(Material Document)、混合表(Hybrid Table)、聚合表(Aggregation Table)和历史表(History Table)之上的。 这些表里面存储着部分冗余信息,用于向应用返回各种查询需求。 数据模型中的大量表,往往会导致库存相关报告运行时的低性能,因为为了显
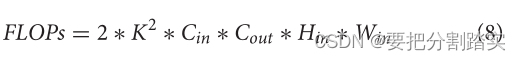
Half-UNet: A Simplified U-NetArchitecture for Medical ImageSegmentation(用于医学图像分割的简化U-Net架构)
摘要:医学图像分割在计算机辅助诊断过程中起着至关重要的作用。近年来,U-Net在医学图像分割中得到了广泛的应用。UNet的许多变体已经被提出,它们试图在保持u型结构不变的情况下提高网络性能。然而,这种u型结构并不一定是最佳的。本文通过实验分析了U-Net的不同部分对分割能力的影响。然后,提出了一种更高效的架构——HalfUNet。所提出的架构本质上是一个基于U-Net结构的编码器-解码器网络,其中

《MapReduce:Simplified Data Processing on Large Cluster》 阅读笔记
介绍 MapReduce是一种编程模式,以及与之相关的用于处理和生成大数据集的实现。其运作方式可以简单概括为以下步骤:一个大的输入被分成很多个小的输入块,同时,一个分布式系统中存在的多个计算机,组成一个大的计算机集群,这些分出来的小的输入块将会被集群中的计算机来执行,由一个 master 机器来分发人物。这些用于计算的机器成为 worker。master 将这个小的输入块分配给 worker,接
《MapReduce:Simplified Data Processing on Large Cluster》 阅读笔记
介绍 MapReduce是一种编程模式,以及与之相关的用于处理和生成大数据集的实现。其运作方式可以简单概括为以下步骤:一个大的输入被分成很多个小的输入块,同时,一个分布式系统中存在的多个计算机,组成一个大的计算机集群,这些分出来的小的输入块将会被集群中的计算机来执行,由一个 master 机器来分发人物。这些用于计算的机器成为 worker。master 将这个小的输入块分配给 worker,接