semantically专题
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练
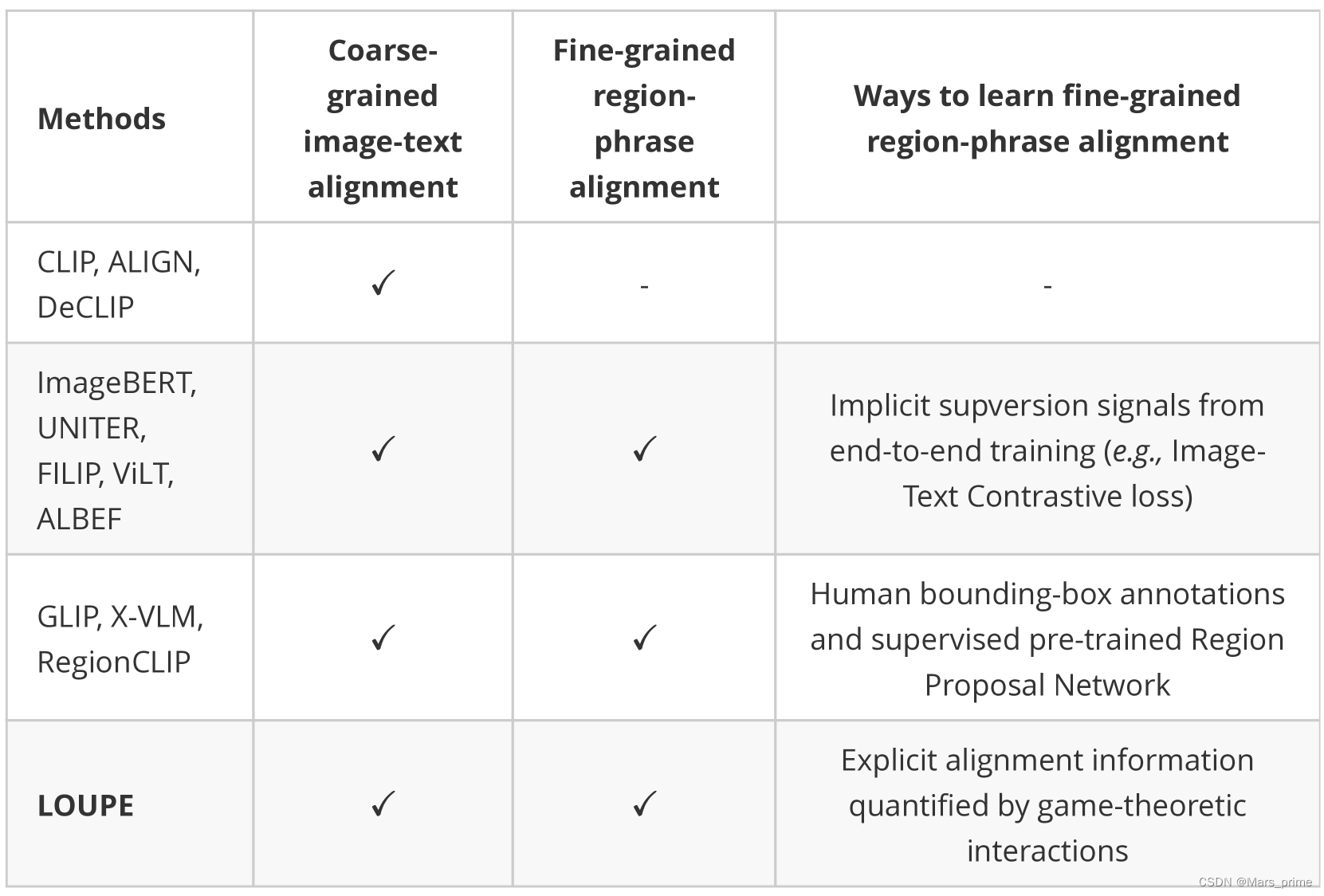
abstract 大规模的视觉语言预训练在广泛的下游任务中显示出令人印象深刻的进展。现有方法主要通过图像和文本的全局表示的相似性或对图像和文本特征的高级跨模态关注来模拟跨模态对齐。然而,他们未能明确学习视觉区域和文本短语之间的细粒度语义对齐,因为只有全局图像-文本对齐信息可用。在本文中,我们介绍放大镜,一个细粒度语义的Ligned visiOn-langUage PrE 训练框架,从博弈论交互的