selenuim专题

selenuim定位
定位红框中的文本内容,此处用到了find_elements_by_css_selector。 组合定位元素表示,标签为啊,class值为KSSActionServer的元素。 content = self.driver.find_element_by_class_name('tabularContents').find_elements_by_css_selector('a[class="KS
UI 自动化测试(Selenuim + Java )
关于 UI 自动化测试工具 selenuim + Java 的环境搭建推荐看Selenium+Java 环境搭建 什么是自动化测试? 自动化测试指软件测试的自动化,在预设状态下运行应用程序或者系统,预设条件包括正常和异常,最后评估运行结果。将人为驱动的测试行为转化为机器执行的过程。 自动化测试包括 UI 自动化,接口自动化,单元测试自动

scrapy+selenuim中间件爬取京东图书有详细思考过程(涉及较广适合练手)
网上很多版本的爬取京东图书都失效了 现在这个版本是能运行的截至到编辑的日期的前后(往后不敢保证) gitee仓库网址:https://gitee.com/cc2436686/jd_book_spider (有详细注释和思考过程) 下面就来看看吧 首先看看我们要爬取的页面 https://book.jd.com/booksort.html 然后用request直接请求在对返
selenuim【1】($x(‘xpath语法’)、WebDriverWait())
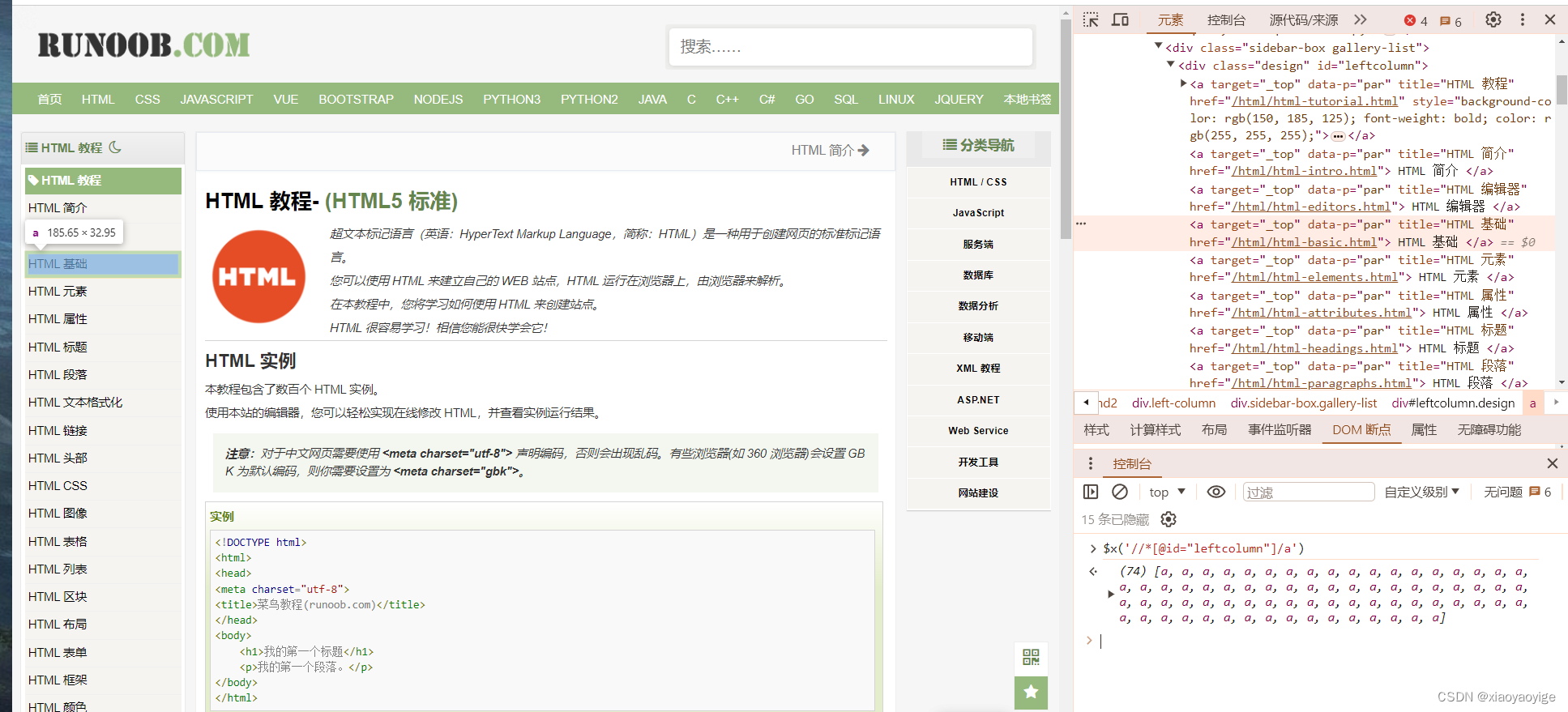
文章目录 初学selenuim记录1、执行driver = webdriver.Chrome()后很久才打开浏览器2、浏览器多元素定位 $x(‘xpath语法’)3、打开浏览器driver.get("网址")执行了很久才开始定位元素:等待(1)driver.set_page_load_timeout(t)(2)WebDriverWait() 初学selenuim记录 1、执行
初学selenuim[1]($x(‘xpath语法’)、WebDriverWait())
文章目录 初学selenuim记录1、执行driver = webdriver.Chrome()后很久才打开浏览器2、浏览器多元素定位 $x(‘xpath语法’)3、打开浏览器driver.get("网址")执行了很久才开始定位元素:等待(1)driver.set_page_load_timeout(t)(2)WebDriverWait() 初学selenuim记录 1、执行
爬虫——ajax和selenuim总结
为什么要写这个博客呢,这个代码前面其实都有,就是结束了。明天搞个qq登录,这个就结束了。 当然也会更新小说爬取,和百度翻译,百度小姐姐的爬取,的对比爬取。总结嘛!!!加油!!! ============================ajax==================================== ,有时爬不到东西,可能是经过Ajax加载的数据,不是原始的HTML文档。