scraper专题

如何使用Web Scraper爬虫抓取数据?
Web Scraper是一个基于Chrome/火狐浏览器的插件,能够在网页上自动爬取数据,提供了丰富的配置,支持自动翻页、登录认证、JavaScript渲染等等,可以解决多数爬虫难题。 Web Scraper的安装也很简单,在Chrome应用商店里搜索“Web Scraper”,找到该插件并点击“添加至Chrome”按钮。 安装好Web Scraper后,需要在开发者工具中使用它,按F12键

如何使用免费的 Instant Data Scraper快速抓取网页数据
Instant Data Scraper 是一款非常简单易用的网页数据爬虫工具,你不需要任何代码知识,只需要点几下鼠标,就可以把你想要的数据下载到表格里面。以下是详细的使用步骤: 第一步:安装 Instant Data Scraper 打开谷歌浏览器,进入 Chrome 网上应用店。搜索 “Instant Data Scraper” 并点击 “添加至Chrome” 按钮。成功安装后,在Chro
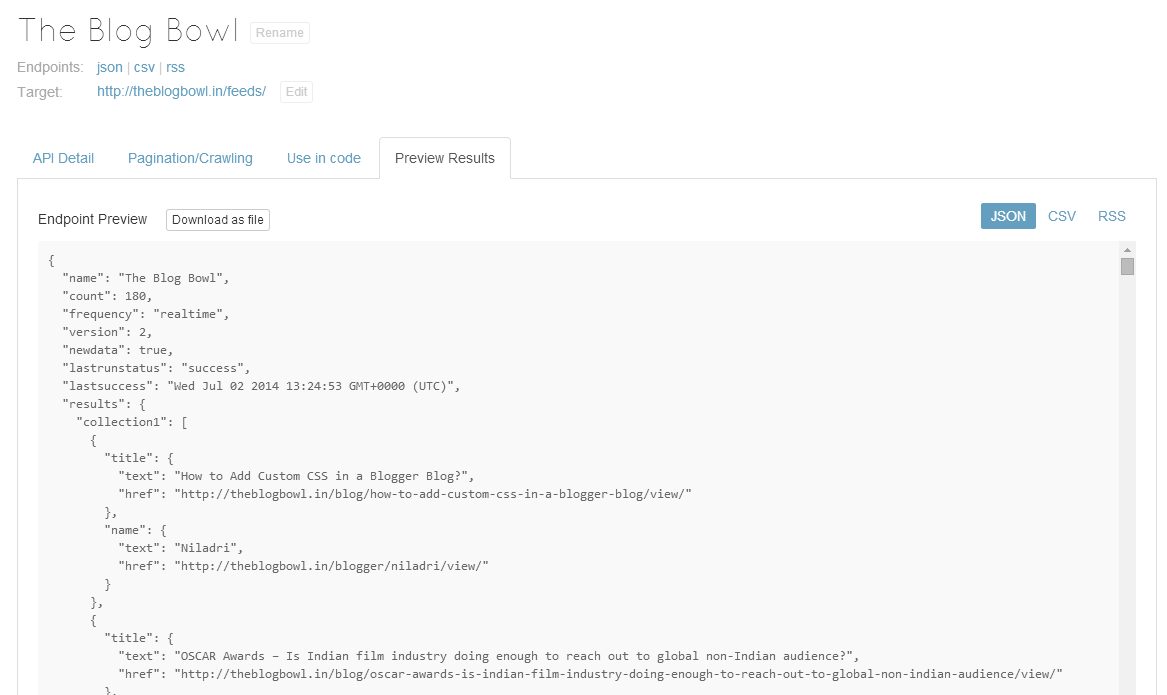
web scraper_Web Scraper和服指南
web scraper Being a frequent reader of Hacker News, I noticed an item on the front page earlier this year which read, “Kimono – Never write a web scraper again.” Although it got a great number of upv
10 分钟上手Web Scraper,从此爬虫不求人
我现在很少写爬虫代码了,原因如下: 网站经常变化,因此需要持续维护代码。爬虫的脚本通常很难复用,因此价值就很低。写简单的爬虫对自己的技能提升有限,对我来不值。 但是不写爬虫,就不能方便的获取数据,自己写代码又要花费很多时间,少则一两个小时,多则半天的时间,这就让人很矛盾。 有没有一种方法可以不写代码,分分钟就就可以实现网页的数据抓取呢? 我去搜了下,还真有,我从这里面选了一个我认为最好用的,那就
![[scrapy.core.scraper] ERROR: Spider error processing](https://img-blog.csdnimg.cn/20200214175552963.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NDg1MjM4Ng==,size_16,color_FFFFFF,t_70)
[scrapy.core.scraper] ERROR: Spider error processing
#scrapy爬虫源代码 #所报的错误全部 本来以为是缺少refer,然后就在settings里面添加了refer:https://github.com/login,发现不起作用 然后又在formrequest中添加了method=‘POST’,还是不行 后来发现所报的bug只有一行与我的源代码有关,“File “f:\Python\爬虫\爬虫学习\第二十三天2.14\github\githu

用Rust和Scraper库编写图像爬虫的建议
本文提供一些有关如何使用Rust和Scraper库编写图像爬虫的一般建议: 1、首先,你需要安装Rust和Scraper库。你可以通过Rustup或Cargo来安装Rust,然后使用Cargo来安装Scraper库。 2、然后,你可以使用Scraper库的Crawler类来创建一个新的爬虫实例。 3、接下来,你可以使用start方法来启动爬虫并开始爬取图像。 以下是一个简单的示例代码,