retrying专题

org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:7359. Already tried 7
错误 : org.apache.hadoop.ipc.Client: Retrying connect to server: localhost/127.0.0.1:7359. Already tried 7 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep 2016-11-25 10:25:24,934 I

python pip 时候出现Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None))
意思就是 连接超时,安装不上, 我们换个地址下载就好了. pip install xxx -i url xxx: 你要下载的库, 自己修改名字 url : pip源 国内几个pip源如下: 阿里云 http://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/

用代理pip install Retrying超时的处理
bug示意: 在使用pip的终端执行如下命令 set https_proxy=http://127.0.0.1:port #port=本地代理端口 终于不用开了代理反复切了

Python库之retrying的高级用法深度解析
Python库之retrying的高级用法深度解析 概述 retrying 是一个Python库,它通过装饰器的方式简化了代码中重试机制的实现。本文将深入探讨retrying库的高级用法,帮助开发者更有效地利用它来增强程序的稳定性和健壮性。 安装 首先,确保你已经安装了retrying库。如果尚未安装,可以通过以下命令进行安装: pip install retrying 基本用法

Retrying,一个神奇优雅的 Python 库
大家好!我是爱摸鱼的小鸿,关注我,收看每期的编程干货。 一个简单的库,也许能够开启我们的智慧之门, 一个普通的方法,也许能在危急时刻挽救我们于水深火热, 一个新颖的思维方式,也许能激发我们无尽的创造力, 一个独特的技巧,也许能成为我们的隐形盾牌…… 神奇的 Python 库之旅,第 4 章 目录 一、Retrying 简介和安装二、重试的艺术三、Retrying 编程示例四、结语五、
Hadoop运行成功但最后显示Redirecting to job history server...Client: Retrying connect to server:
运行环境:ubuntu 自己生成了个jar包,用hadoop jar xxx.jar ./input ./output,运行成功,可以输出结果,但是最后提示Redirecting to job history server...Client: Retrying connect to server: 具体如下: 16/06/22 21:51:23 INFO mapred.ClientSer

使用Guava Retrying优雅的实现业务异常重试
上次写过一篇如何使用spring retry来实现业务重试的文章:https://blog.csdn.net/Kingsea442/article/details/135341747 尽管 Spring Retry 工具能够优雅地实现重试,但它仍然存在两个不太友好的设计: 重试实体被限定为 Throwable 子类,这意味着重试针对的是可捕获的功能异常,但实际上我们可能希望依赖某个数据对

Error: INFO ipc.Client: Retrying connect to server: Already tried XXX time(s).
首先,这个坑逼错误可能是由于端口号没有开启导致的(比如9000端口),使用命令查看一下相应端口号是否存在。 sudo netstat -tpnl 若看到9000端口,则说明端口号正常开启,导致报错的原因是主节点9000端口打开了,但是不允许远程访问。 若未看到9000端口,说明datanode以及namenode没有成功启动,此时可以看一下配置文件(core-site.xml以及hdf

flink yarn-session 启动失败retrying connect to server 0.0.0.0/0.0.0.0:8032
原因分析,启动yarn-session.sh,会向resourcemanager的端口8032发起请求: 但是一直无法请求到8032端口,触发重试机制会不断尝试 备注:此问题出现时,我的环境ambari部署的HA 高可用hadoop,三个节点node104、node105、node106,其中node105和node106为resourcemanager载体,node1

There appears to be trouble with your network connection. Retrying
一直在报如上错误,试了很多办法,比如删掉yarn.lock,yarn cache clean,删掉node_modules,rm proxy等等都没有用 甚至于重启电脑,然而并没有什么用 突然间想到,我用了clash for window 所以想了下,应该要设置proxy 先查电脑的ip cmd --> ipconfig 然后设置proxy yarn config set proxy
info There appears to be trouble with your network connection. Retrying...
问题 安装依赖yarn install或npm i 时,如果遇到提示 info There appears to be trouble with your network connection. Retrying... 解决办法 删除yarn.lock或package-lock.json 文件,重新执行yarn install或npm i 就可以了
python的pip安装第三方包时报“WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status”
pip安装第三方包时报 WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by ‘NewConnectionError(’<pip._vendor.urllib3.connection.VerifiedHTTPSConnect

Java 开源重试类 guava-retrying 使用案例
使用背景 需要重复尝试执行某些动作,guava-retrying 提供了成型的重试框架 依赖 <dependency><groupId>com.github.rholder</groupId><artifactId>guava-retrying</artifactId><version>${retrying.version}</version><exclusions><exc

error_log塞满了70+G的错误日志。Notifier for subscription 94 (dbus://) went away, retrying!
电脑被/var/log/cups/error_log塞满错误日志,达到了70+G的大小,直接把硬盘塞满了。 我删了之后,还是会源源不断出现问题,就去看看了哪里报错。 显示: File \"/usr/lib/cups/notifier/dbus\" has insecure permissions (0100777/uid=0/gid=0). Notifier for subscri
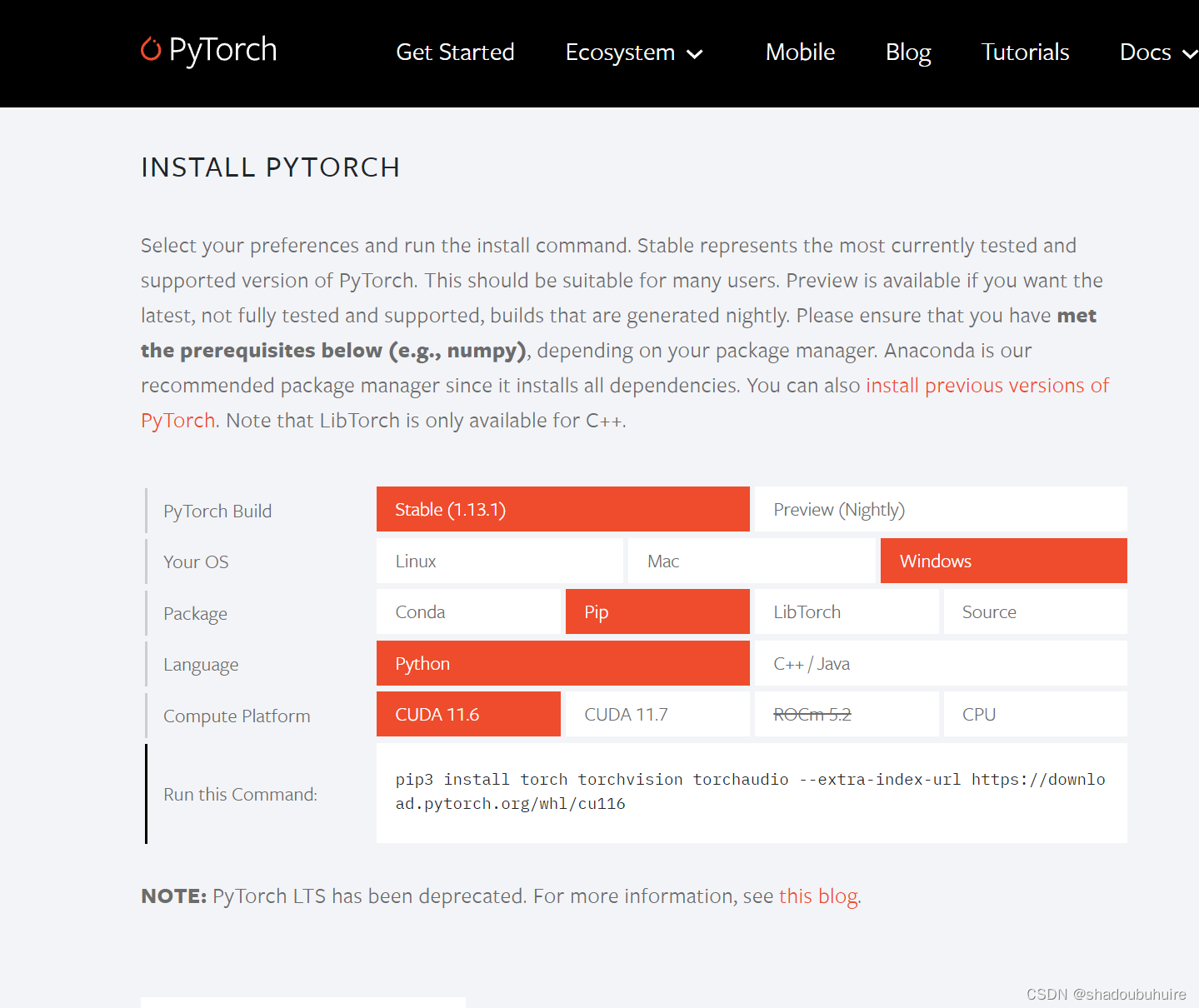
安装pytorch.cuda时出现Solving environment: failed with initial frozen solve. Retrying with flexible solve
使用了网上大家说的更新conda,以及更换镜像均无法解决。便尝试使用pip安装指令。 1、将清华镜像源添加到PIP的搜索目录中,打开ANACONDA PROMPT,键入 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple 2、进入PYTORCH官网,选择适合自己电脑系统的版本,在这里查看不同显卡

安装pytorch出现的问题Solving environment: failed with initial frozen solve. Retrying with flexible solve
此问题的解决最终还是回归到版本不同步问题 两个箭头处的版本要一致才行。 具体参考:win10下pytorch和CUDA的安装完整过程_chon机械师的博客-CSDN博客