rdds专题

spark,keyValue对RDDs
keyValue对RDDs 创建keyValue对RDDs: 使用map()函数,返回key/value对 例如,包含数行数据的RDD,每行数据的第一个单词作为keys,整行作为value val rdd=sc.textFile("/home/hellospark.txt") rdd.foreach(println) val rdd2= rdd.map(line=>(lines.spl
Rdds基本操作Action
Rdds基本操作Action action,在RDD上计算出一个结果 把结果返回给driver program或保存在文件系统,count(), save reduce() 接受一个函数,作用在RDD两个类型相同的元素上返回一个新元素 实现元素累加,计数,和其他类型的聚集操作 val rdd=sc.parallelize(Array(1,2,3,3)) rdd.collect(

Rdds基本操作Transformation,逐元素,map,filter,flatMap,集合运算
Rdds基本操作Transformation 转换,从之前的RDD构建一个新的RDD,map操作 逐元素map,接受一个函数,应用在RDD每一个元素,并返回一个新的RDD val lines = sc.parallelize(Array("hello","spark","hello","world","!")) 测试时候使用,从已有集合中构造一个RDD lines.foreach
spark Rdds介绍
Driver program: 包含main方法,RDDs定义和操作 管理很多节点,executors SparkContext: Driver program通过spark context对象访问spark, 代表和一个集群的连接,在shell中自动创建好,就是sc RDDs, 弹性分布式数据集Resilient distributed datasets,并行分别在集群

从RDDs到Spark
这哥们的论文用大白话讲的非常好,再次致敬一下。 转载URL:http://blueve.me/archives/1437 Spark是近年来非常火爆的分布式计算框架,可以说它紧跟Hadoop的脚步,并且在很多方面实现了超越。在Spark官方的宣传中我们也可以看到,Hadoop能做到的事情,Spark也可以做,而且通常可以做得更好。事实上,越来越多的业内公司都开始试水Spar

RDDs, Spark Memory, and Execution
弹性分布式数据集 (RDDs) 目的 / 动机Sprak的实现https://www.usenix.org/system/files/conference/nsdi12/nsdi12-final138.pdf 2014 ACM Doctoral Dissertation Award (Matei Zaharia, Spark creator, Databricks cofounder) 为什么
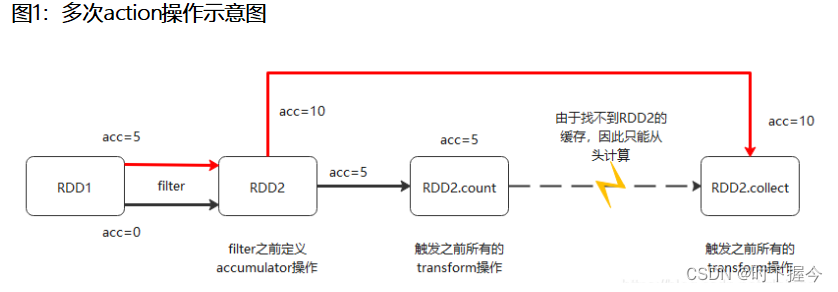
Spark - Resilient Distributed Datasets (RDDs)介绍
目录 RDD介绍 RDD构建 RDD分区数 RDD算子 Transformation算子 Action算子 RDD持久化 RDD缓存 检查点 RDD共享变量 广播变量 累加器Accumulator RDD介绍 Resilient Distributed DataSets,弹性分布式数据集,可以把RDD看作一种分布式集合。其RDD本身不存储数据,数据