ragas专题

LLM之基于Ragas利用本地数据、本地模型构造测试数据集,测试RAG
前言 这回还是粗略写写前言吧,构建好RAG系统之后,你总得去进行测试吧,那么如何测试呢?用什么指标去衡量呢?测试数据集怎么构建呢? 这里使用Ragas对RAG系统进行测试,而Ragas又基本是OPENAI的接口,那是要钱钱的,所以就研究使用本地模型去跑 Ragas简介 不想写,有空再写 github地址:ragas ragas测试用例数据集: 1、

AI大模型探索之路-应用篇11:AI大模型应用智能评估(Ragas)
目录 前言 一、为什么要做智能评估? 二、Ragas是什么? 三、Ragas使用场景 四、Ragas评估指标 五、Ragas代码实践 总结 前言 随着人工智能技术的飞速发展,AI大模型(LLM)已经成为了推动技术创新和应用的关键因素。这些大模型在语言理解、图像识别、自然语言生成等领域展现出了惊人的能力。然而,随着模型规模的增大,它们对计算资源的消耗、环境适应性、模
自然语言处理: 第十七章RAG的评估技术RAGAS
论文地址:[2309.15217] RAGAS: Automated Evaluation of Retrieval Augmented Generation (arxiv.org) 项目地址: explodinggradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipeline

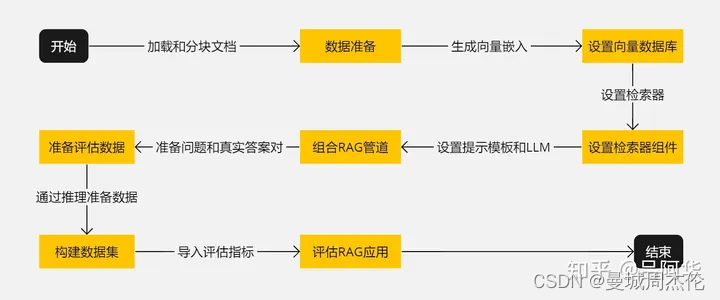
使用 RAGAs(检索增强生成评估)评估 RAG 应用
原文地址:Evaluating RAG Applications with RAGAs 一个包含指标和大型语言模型生成的数据框架,用于评估您的检索增强生成管道的性能。 2023 年 12 月 13 日 Stylized performance dashboard for Retrieval-Augmented Generation 到目前为止,我们知道为检索增强生成 (RAG) 的应用