quantized专题
![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs
引言 今天带来LoRA的量化版论文笔记——QLoRA: Efficient Finetuning of Quantized LLMs 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 我们提出了QLoRA,一种高效的微调方法,它在减少内存使用的同时,能够在单个48GB GPU上对65B参数的模型进行微调,同时保持16位微调任务的完整性能。QLoRA通过一个冻结的4位量化预
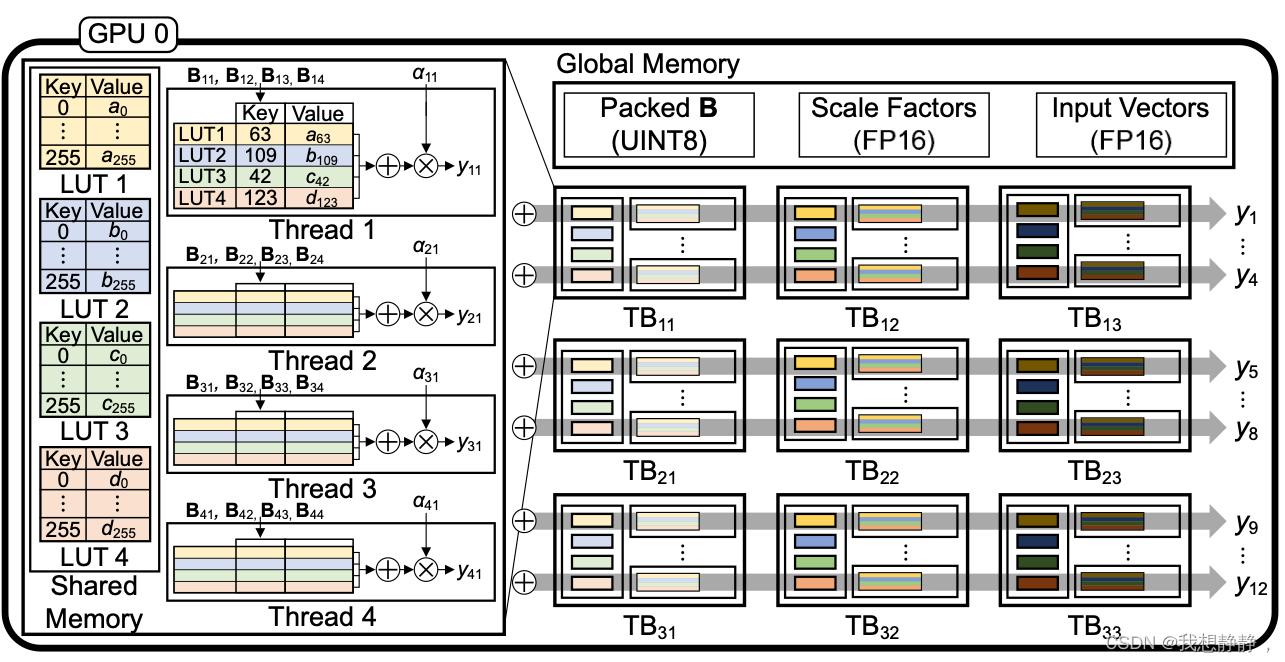
LUT-GEMM: Quantized Matrix Multiplication based on LUTs for Efficient Inference in Large-Scale Gener
文章目录 abstractintroduction背景量化二值量化BCQ LUT-GEMM二值量化扩展Group-wise 𝛼分配基于LUT的量化矩阵乘法LUT-GEMM内存占用 实验Simple Comparisons with Various KernelsComparison with FP16 Tensor ParallelismExploration of Compressio

SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression翻译
摘要 大型语言模型(LLM)预训练的最新进展获得了具有令人印象深刻能力的高质量LLM。通过量化将这种LLM压缩至每个参数3-4位,从而可以适配内存有限的设备,例如笔记本电脑和手机,从而实现个性化使用。但是,将每个参数的量化至3-4位通常会导致中度到高度的准确率损失,尤其是对于1-10B参数范围内的较小模型,而这些非常适合边缘部署。为了解决这个准确性问题,我们介绍了一种Sparse-Quantiz