pypdf2专题

Python 处理 PDF 文件(PyPDF2, ReportLab)
Python 是一门强大的编程语言,在处理PDF文件方面有着丰富的库支持,其中最常用的两个库是 PyPDF2 和 ReportLab。PyPDF2 主要用于读取、拆分、合并和修改已有的PDF文件,而 ReportLab 则擅长生成新的PDF文件。 一、PyPDF2 1. PyPDF2 概述 PyPDF2 是一个纯 Python 库,主要用于操作已有的 PDF 文件。它的功能包括从 PDF 中
![[python3] pypdf2 处理书签](/front/images/it_default.jpg)
[python3] pypdf2 处理书签
pypdf4 能添加书签,但是没有跳转功能 (PyPDF2好像还不能读取书签数据) https://pythonhosted.org/PyPDF2/index.html #!/mingw64/bin/python3# -*- coding: utf-8 -*-from PyPDF2 import PdfFileWriter, PdfFileReader, PdfFileMerger, gen
使用pypdf2把原始pdf转换成kindle看着舒适的pdf
文章目录 裁剪pdf使用脚本拆分页面并转成kindle可见的大小压缩pdf(可选) 拆分pdf 由于买了个kindle,所以想要最大效率地利用它。而在kindle上看pdf是很难受的,因为kindle屏幕太小,展示一个页面字体基本看不清。 因此,我写了个python脚本,配合acrobat使用能够把原始的pdf,尤其是A4页面格式的pdf转换成kindle看着舒适的pdf。使用方法
在 Python 中使用 PyPDF2 向 PDF 文件批量添加水印
目录: 使用 PyPDF2 添加水印到 PDF 文件批量添加水印到 PDF 文件所有页 PDF 文件广泛用于不同的设备和平台上,在某些情况下,可能需要在 PDF 文件中申明版权,需要将水印、条形码、二维码等添加到 PDF 中。PyPDF2 提供了一种将另一个 PDF 文件作为水印,添加到 PDF 文件的方法。 在下面的示例中,制作一个 PDF 水印文档,可以加入文字、二维码,通

关于PyPDF2 3.0.0版本中方法的更新
PyPDF2.errors.DeprecationError: mediaBox is deprecated and was removed in PyPDF2 3.0.0. Use mediabox instead. 这里你需要将使用到mediaBox方法的地方,变成mediabox PyPDF2.errors.DeprecationError: getLowerLeft_x is depr
python:PyPDF2 从PDF文件中提取目录
我发现 pypdf 和 pypdf2 的作者是同一人:Mathieu Fenniak pip install pypdf2 ; pypdf2-3.0.1-py3-none-any.whl (232 kB) 编写 pdf_read_dir.py 如下 # -*- coding: utf-8 -*-""" pypdf2==3.0.1 从PDF中提取目录 """import os

python:PyPDF2 从PDF中提取目录
我发现 pypdf 和 pypdf2 的作者是同一人:Mathieu Fenniak pip install pypdf2 ; pypdf2-3.0.1-py3-none-any.whl (232 kB) 编写 pdf_read_dir.py 如下 # -*- coding: utf-8 -*-""" pypdf2==3.0.1 从PDF中提取目录 """import os
用Python库PyPDF2操作PDF文件
PDF是Portable Document Format的缩写,这类文件通常使用.pdf作为其扩展名。在日常开发工作中,最容易遇到的就是从PDF中读取文本内容以及用已有的内容生成PDF文档这两个任务。 从PDF中提取文本 在Python中,可以使用名为PyPDF2的三方库来读取PDF文件,可以使用下面的命令来安装它。 pip install PyPDF2 PyPDF2没有办法从PDF文档

Py之PyPDF2:PyPDF2的简介、安装、使用方法之详细攻略
Py之PyPDF2:PyPDF2的简介、安装、使用方法之详细攻略 目录 PyPDF2的简介 PyPDF2的安装 PyPDF2的使用方法 1、基础用法 PyPDF2的简介 PyPDF2是一个免费的、开源的纯python PDF库,能够拆分、合并、裁剪和转换PDF文件的页面。它还可以为PDF文件添加自定义数据、查看选项和密码。PyPDF2也可以从pdf中检索文本

PyPDF2如何实现按照PDF页码提取后并另存为PDF格式文件?
事情的经过是这样的,由于现有的PDF文件太多了而我真正需要的内容只有十几页。 每次查找不方便,另外需要发给自己的小伙伴也太多别人也不容易找到需要的内容,所以产生了一个想法就是把需要的PDF提取出来然后另存为一个PDF文件。 于是就有了这次的PDF页面提取操作,下面进入实战环节。 项目中用到的库主要是PyPDF2用于PDF格式文件的提取等操作,另外还需要os操作库用来做文件的读写、另存为操作。
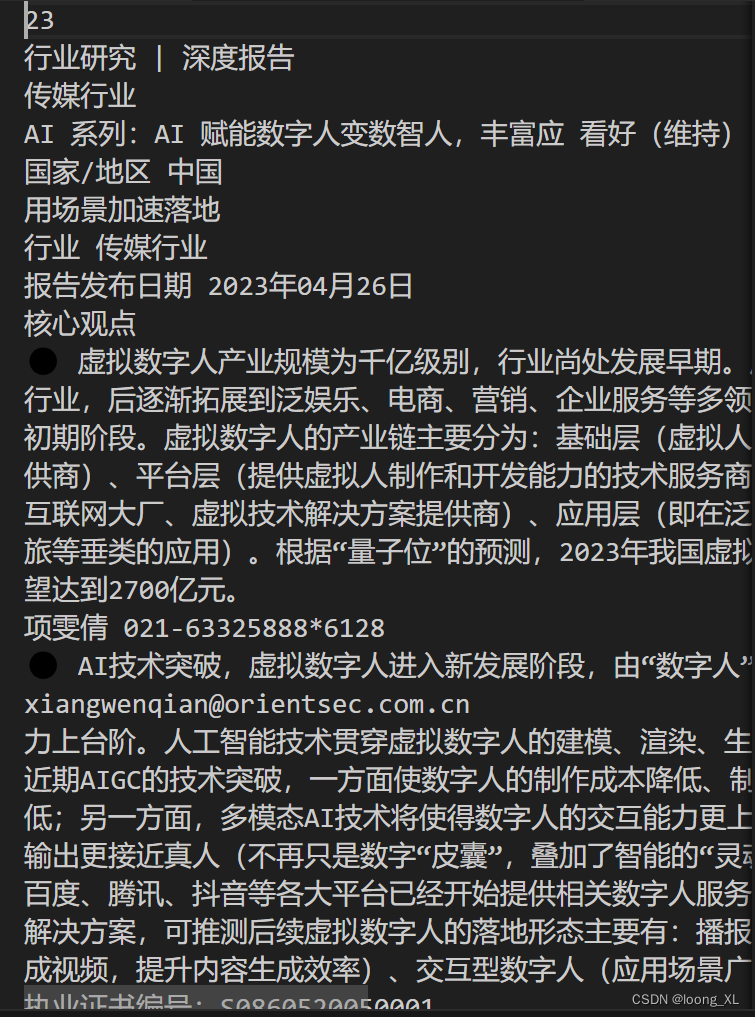
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com 代码: import pdfplumberwith pdf
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com 代码: import pdfplumberwith pdf