pretrained专题

NLP pretrained model
最近听了NLP pretrained model的报告,感觉挺有意思的。此处大量参考从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Word Embedding 词向量在自然语言处理中有着重要的角色,它将抽象的词语之间的语义关系量化成向量形式。有了良好的词向量,我们就可以做更多的工作。目前构建词向量的方式大体上分成两大类: 统计方法:通过统计词语之间的关
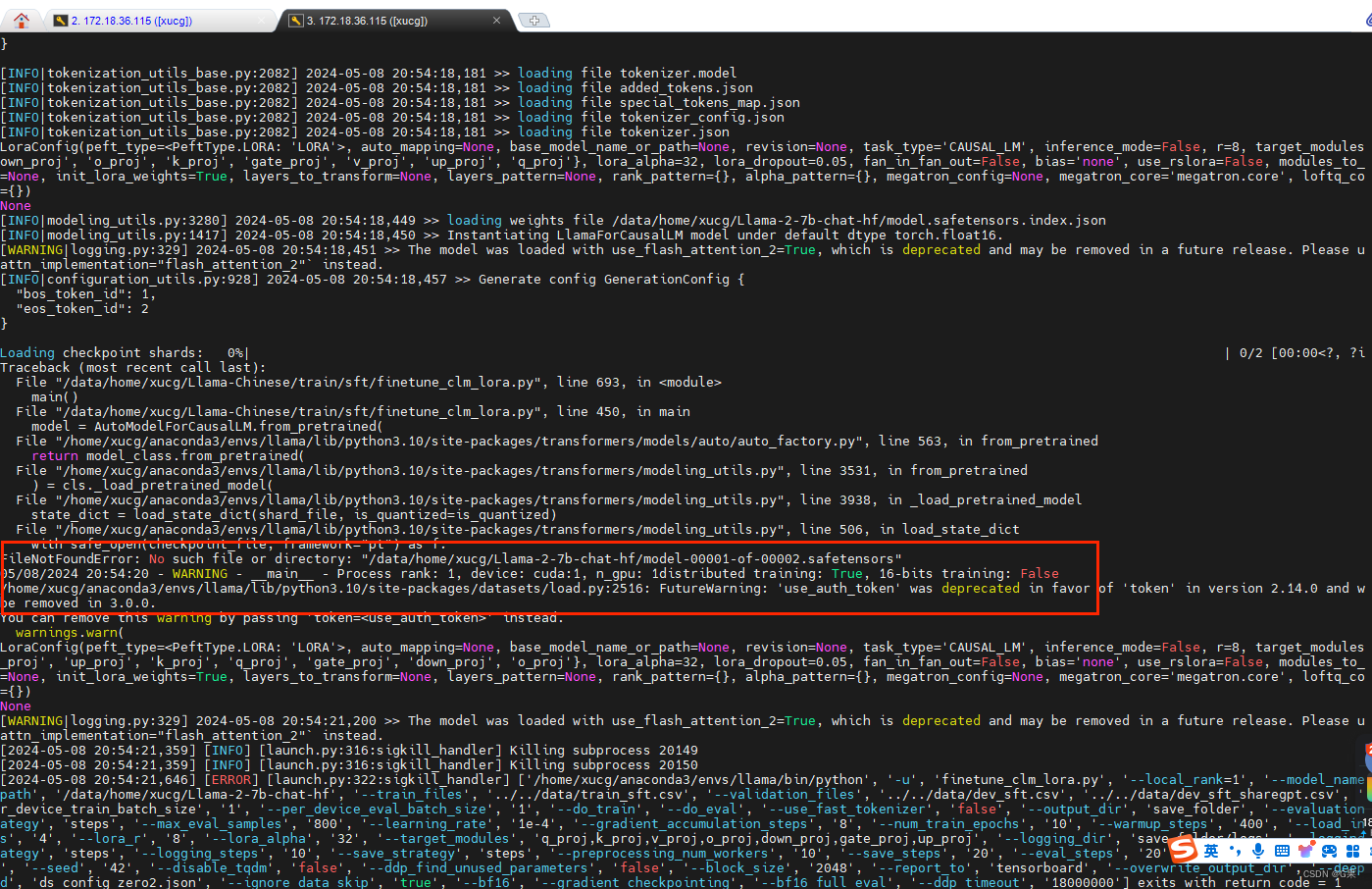
AutoModelForCausalLM.from_pretrained 函数调用本地权重报错
文章目录 1、代码报错的位置(前情提要)finetune_lora.shfintune_clm_lora.py 2、报错截图2.1、huggingfaces上的 meta-llama/Llama-2-7b-chat-hf2.2、服务器上模型文件路径 3、特别注意事项 1、代码报错的位置(前情提要) 在终端直接运行finetune_lora.sh文件,–model_name_or_

AutoTokenizer.from_pretrained 与BertTokenizer.from_pretrained
AutoTokenizer.from_pretrained 和 BertTokenizer.from_pretrained 都是 Hugging Face 的 Transformers 库中用于加载预训练模型的 tokenizer 的方法,但它们之间有一些区别。 灵活性: AutoTokenizer.from_pretrained:这个方法是灵活的,可以用于加载任何预训练模型的 tokeniz
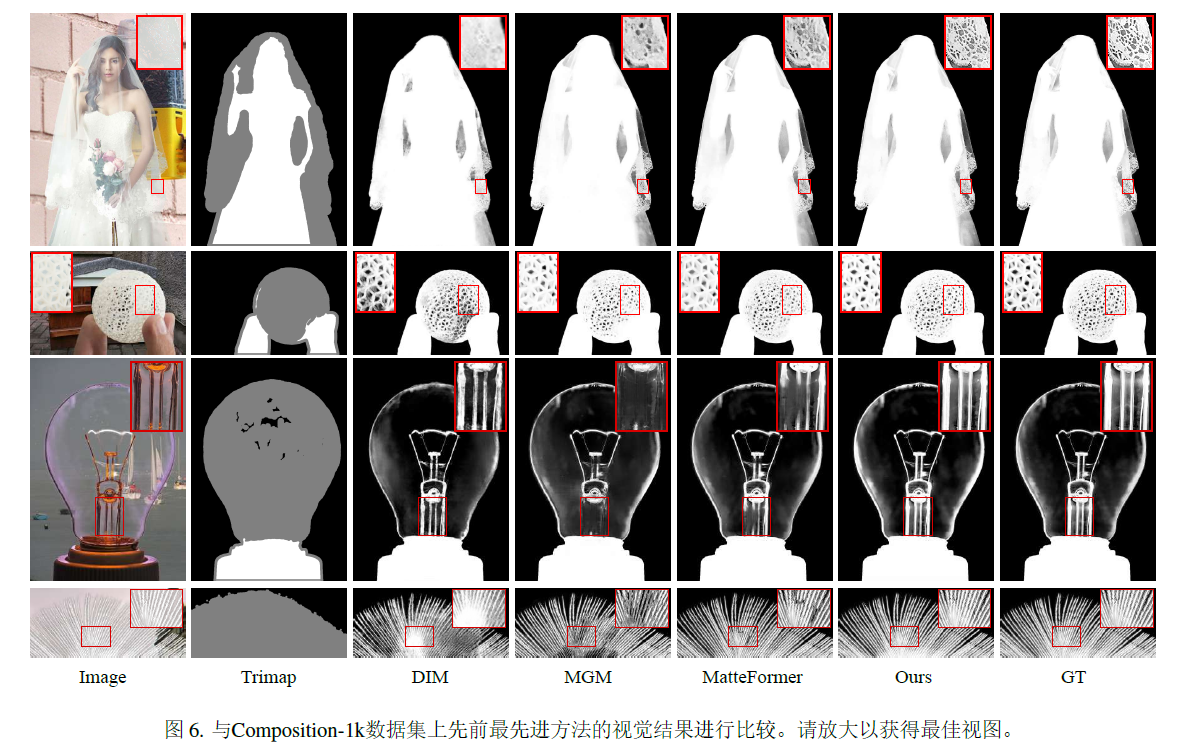
ViTMatte:Boosting image matting with pretrained plain vision transformers
自sora之后,我也要多思考,transformer的scaling law在各个子领域中是不是真的会产生智能,conv的叠加从resnet之后就讨论过,宽或者深都没有办法做到极限,大概sam这种思路是最好的实证。 1.introduction 引入了ViT adaptation策略和detail capture module。 2.Methodology 2.2 Overall ar

huggingface 连不上 from_pretrained from_single_file
huggingface的缓存目录 ~/.cach cd ~/.cache# pwd 后展示 /home/fxbox/.cachepwd pipe: StableDiffusionPipeline = StableDiffusionPipeline.from_pretrained(model_id_or_path,).to(device=self.device, dtype=self.

ACL 2020 Video-Grounded Dialogues with Pretrained Generation Language Models
动机 预训练好的语言模型在改善各种下游NLP任务方面已显示出显著的成功,这是由于它们能够在文本数据中建立依赖关系和生成自然反应。本文利用预训练好的语言模型来提高视频对话的效果。基于Transformer的预训练好的语言模型的神经结构已经被用来学习视觉-文本NLP任务的跨模态表征。它可以应用于捕捉不同类型输入模式(文本和图像)之间的各种依赖关系,并具有适当的客观损失函数。这些模型的多头attent

Mask Scoring R-CNN,代码运行报错KeyError: ‘Non-existent config key: MODEL.PRETRAINED_MODELS‘
这几天在做Mask Scoring R-CNN算法运行,可是运行 命令: python tools/train_net.py --config-file configs/e2e_mask_rcnn_R_50_FPN_1x.yaml 总是报错: KeyError: 'Non-existent config key: MODEL.PRETRAINED_MODELS' 我是根据,下面几个博客进行