pdfplumber专题

pdfplumber - pdf 数据提取
文章目录 一、关于 pdfplumber安装 二、命令行界面1、基本示例2、选项 三、Python库1、基本示例2、加载PDF3、`pdfplumber.PDF`类4、`pdfplumber.Page` 类5、对象`char`特性`line`属性`rect`属性`curve` 属性派生属性`image`属性 6、通过pdfminer获取更高级别的`pdfminer.six` 四、可视化调试1
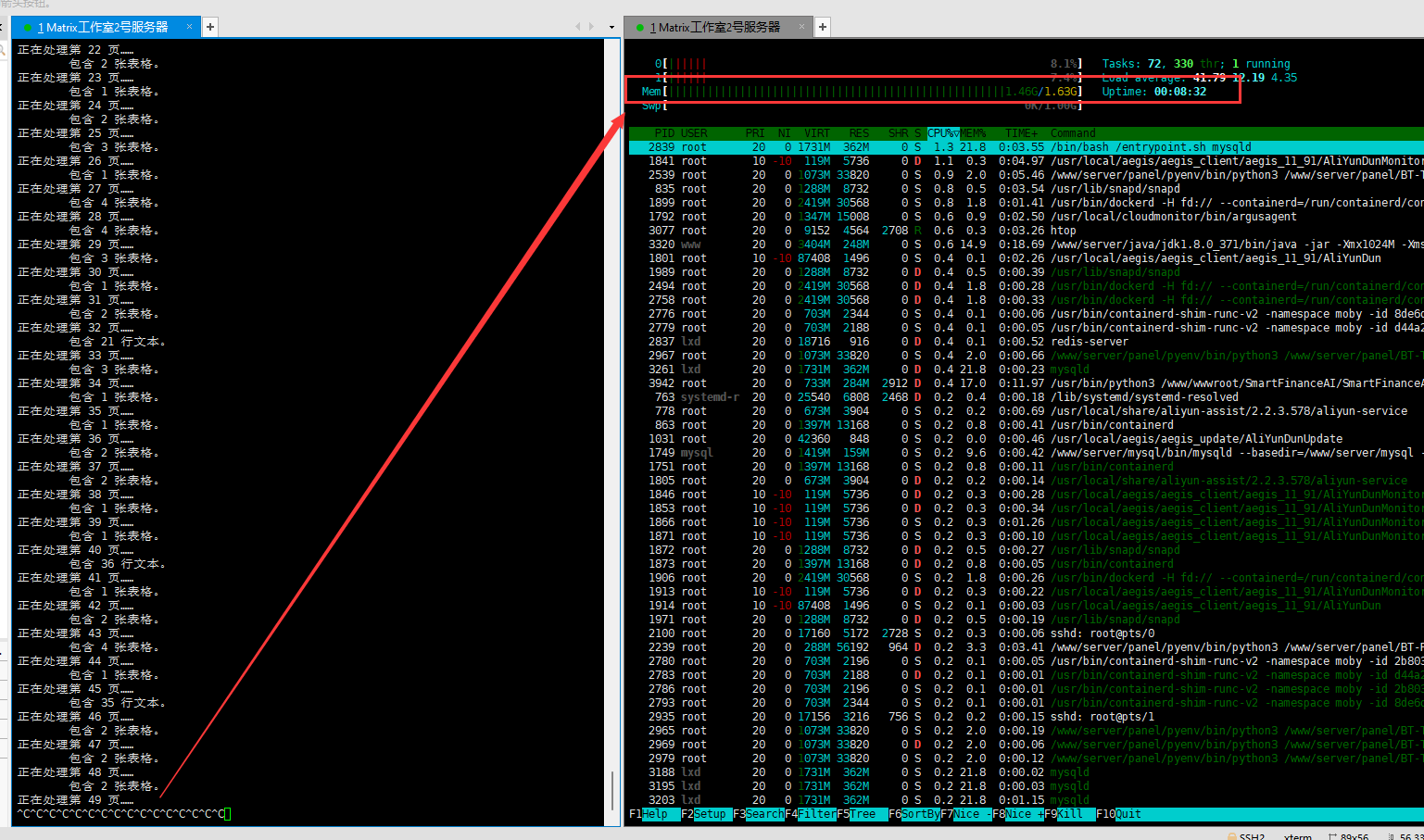
记一次 pdfplumber 内存泄漏导致的服务器宕机
有一个项目需求,要在每天凌晨5点的时候执行一个任务,获取一系列的PDF文件并解析。 后端是Django框架,定时任务用Celery来实现的。 本地跑没什么问题,但是一放到服务器上跑就会宕机,而且是毫无征兆的宕机,至少在宝塔面板上看到的宕机前的负载、CPU使用率和内存占用率还是正常的。 一开始以为是Celery的问题,但是排查了很久都没发现有啥问题,尤其是这个脚本在本地是可以跑的。 于是我就

PDFPlumber解析PDF文本报错:AssertionError: (‘Unhandled’, 6)
文章目录 1、问题描述2、问题原因3、问题解决 1、问题描述 今天在使用PDFPlumber模块提取PDF文本时extract_text()方法报错,报错内容如下: Traceback (most recent call last):......File "F:\Python\...\site-packages\pdfminer\pdffont.py", l

Python 与 pdfplumber:高效自动读取 PDF 的解决方案
在许多数据处理和信息提取任务中,处理 PDF 文件可能是一个具有挑战性的过程。幸运的是,Python 提供了许多库来简化这个任务,其中 pdfplumber 是一个功能强大且易于使用的库。在本文中,我们将探讨如何使用 Python 和 pdfplumber 库高效地自动读取 PDF 文件。 什么是 pdfplumber? pdfplumber 是一个用 Python 编

深入探索pdfplumber:从PDF中提取信息到实际项目应用【第94篇—pdfplumbe】
深入探索pdfplumber:从PDF中提取信息到实际项目应用 在数据处理和信息提取的过程中,PDF文档是一种常见的格式。然而,要从PDF中提取信息并进行进一步的分析,我们需要使用适当的工具。本文将介绍如何使用Python库中的pdfplumber库来读取PDF文档,并通过实际代码示例演示如何将提取的信息写入Excel文件。 1. pdfplumber简介 pdfplumber是一个用于

Python-pdfplumber读取PDF内容
文章目录 import pdfplumberimport pandas as pdwith pdfplumber.open("path/to/file.pdf") as pdf:first_page = pdf.pages[0]# 获取文本,直接得到字符串,包括了换行符【与PDF上的换行位置一致,而不是实际的“段落”】print(first_page.extract_tex
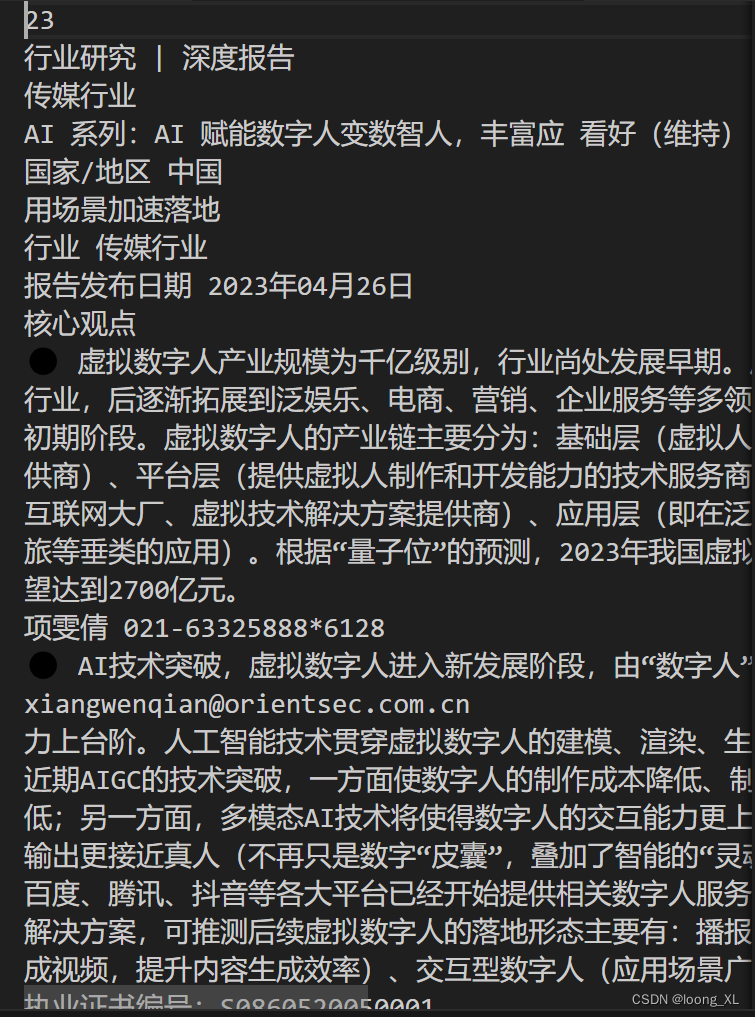
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com 代码: import pdfplumberwith pdf
pdf文档内容提取pdfplumber、PyPDF2
测试pdfplumber识别效果好些;另外pdf这两个如果超过20多页就没法识别了,结果为空 1、pdfplumber 安装:pip install pdfplumber -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com 代码: import pdfplumberwith pdf