pdfminer专题

Python 3.6 中使用pdfminer解析pdf文件
所使用python环境为最新的3.6版本 一、安装pdfminer模块 安装anaconda后,直接可以通过pip安装 pip install pdfminer3k 如上图所示安装成功。 二、在IDE中进行编码 #!/usr/bin/env python# encoding: utf-8"""@author: wugang@software: PyCharm@file: p
【记录】Python3| 将 PDF 转换成 HTML/XML(✅⭐pdfminer.six)
本文将会被汇总至 【记录】Python3|2024年 PDF 转 XML 或 HTML 的第三方库的使用方式、测评过程以及对比结果(汇总),更多其他工具请访问该文章查看。 注意!pdfminer.six 和 pdfminer3k 不是同一个!!! 文章目录 PDFMiner.six 使用体验与评估1 安装指南2 测试代码3 测试结果3.1 转 html 的结果3.2 转 xml

ImportError: cannot import name ‘open_filename‘ from ‘pdfminer.utils‘已搞定
报错内容 ImportError: cannot import name ‘open_filename’ from ‘pdfminer.utils’ 第一步:pip uninstall pdfminer 解决办法 pip3 install pdfminer.six 注意不要 pip install pdfminer.six 是安装不了的

PDFMiner:python 读取 pdf 内容
PDF的格式不是规范的,很多情况下没有逻辑结构,不能自适应页面大小的调整。PDFMiner是通过尝试猜测PDF的布局来重建其结构,有时候效果并不理想。 import importlibimport sysimport timeimportlib.reload(sys)time1 = time.time()import os.pathfrom pdfminer.pdfparser impo

PDFMiner,一个神奇的 Python 库!
更多资料获取 📚 个人网站:ipengtao.com 大家好,今天为大家分享一个神奇的 Python 库 - pdfminer。 Github地址:https://github.com/euske/pdfminer 在数字化时代,PDF(Portable Document Format)文档广泛用于存储和共享信息。但是,有时我们需要从PDF文档中提取文本和数据以进行进一步分析或处
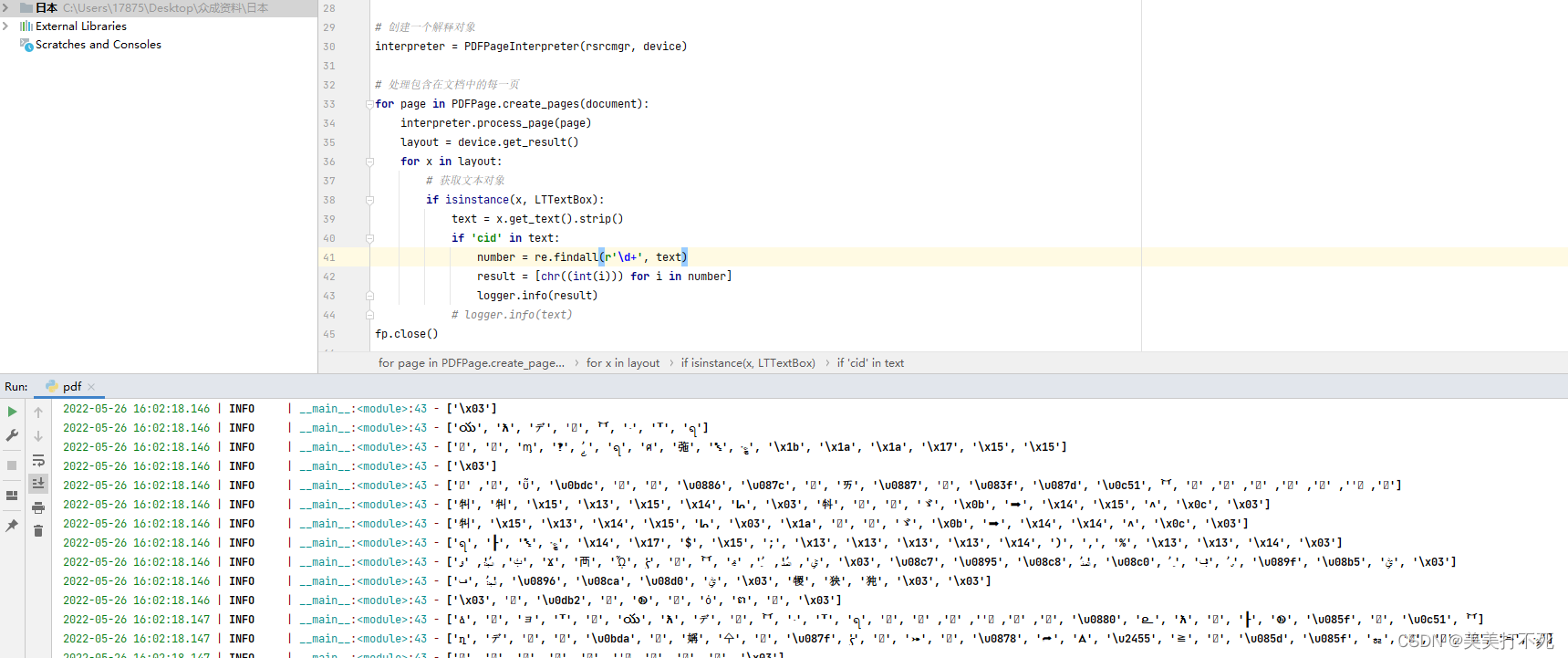
Python使用pdfminer库解析pdf得到的一大堆CID和数字如何处理
这个是我识别pdf的代码 from pdfminer.pdfparser import PDFParserfrom pdfminer.pdfdocument import PDFDocumentfrom pdfminer.pdfpage import PDFPagefrom pdfminer.pdfinterp import PDFResourceManagerfrom pdfminer