partitioner专题

MapReduce 自定义partitioner
需求:将以下数据进行分开处理,其中第六个字段表示开奖结果数值,现在以15为分界点,将15以上的结果保存到一个文件,15以下的结果保存到一个文件。 (以图片数据为例) 定义mapper类: import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.h

python 实现Hadoop的partitioner和二次排序
我们知道,一个典型的Map-Reduce过程包 括:Input->Map->Patition->Reduce->Output。Pation负责把Map任务输出的中间结果 按key分发给不同的Reduce任务进行处理。Hadoop 提供了一个非常实用的partitioner类KeyFieldBasedPartitioner,通过配置相应的参数就可以使用。通过 KeyFieldBasedPartiti
Hadoop Streaming 实战: 实用Partitioner类KeyFieldBasedPartitioner
我们知道,一个典型的Map-Reduce过程包括:Input->Map->Patition->Reduce->Output。Pation负责把Map任务输出的中间结果按key分发给不同的Reduce任务进行处理。Hadoop 提供了一个非常实用的partitioner类KeyFieldBasedPartitioner,通过配置相应的参数就可以使用。通过KeyFieldBasedPartitione
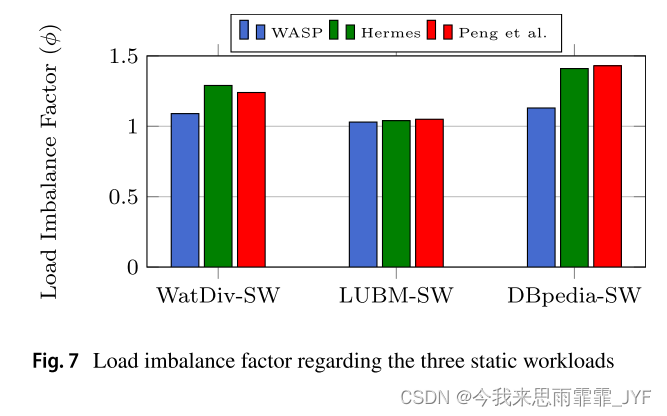
A Workload‑Adaptive Streaming Partitioner for Distributed Graph Stores(2021)
用于分布式图存储的工作负载自适应流分区器 对象:动态流式大图 划分方式:混合割 方法:增量重划分 考虑了图查询算法,基于动态工作负载 考虑了双动态:工作负载动态;图拓扑结构动态 缺点:分配新顶点时不做过多处理(不考虑初始化分的均衡),仅通过散列的方式分配节点,仅对变化后的图分区进行顶点重分配,需要维护所有节点中的活动顶点,对每个活动顶点进行计算,才能确定需要重新分配的顶点。 摘要: 流式

【大数据面试知识点】分区器Partitioner:HashPartitioner、RangePartitioner
Spark HashParitioner的弊端是什么? HashPartitioner分区的原理很简单,对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID;弊端是数据不均匀,容易导致数据倾斜,极端情况下某几个分区会拥有rdd的所有数据。 RangePartitioner分区的原理及特点? 原理

Hadoop之MapReduce框架Partitioner分区
1 Partitioner分区 1.1 Partitioner分区描述 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,按照手机号码段划分的话,需要把同一手机号码段的数据放到一个文件中;按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文