nodemanager专题

yarn resourceManager 找不到nodeManager
尤其注意:master和slave都要配置 1首先是配置core-site.xml (注意:主机配置下hapoop缓存目录 <property> <name>hadoop.tmp.dir</name> <value>/hadoop_tmp</value> </property> ) <configuration> <property>

NodeManager本地缓存源码解析
NodeManager本地缓存源码解析 NodeManager本地缓存中资源有三种可见度:PUBLIC、PRIVATE、APPLICATION,每种可见度都需要不同的处理 PUBLIC:全局共享缓存,资源存放在 ${yarn.nodemanager.local-dirs}/filecache/ 目录下 PRIVATE:对应用户级别共享资源,资源存放在 y a r n . n o d
Hadoop-Yarn-NodeManager是如何监控容器的
一、源码下载 下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧 Index of /dist/hadoop/core 二、上下文 在我的博客<Hadoop-Yarn-NodeManager是如何启动容器的>中的ContainerLaunch prepareForLaunch()会触发ContainerEventType.CONTAINER_LAUN

Hadoop-Yarn-NodeManager如何计算Linux系统上的资源信息
一、上下文 <Hadoop-Yarn-NodeManager都做了什么>中讲节点资源监控服务(NodeResourceMonitorImpl)时只是提了下SysInfoLinux,下面我们展开讲下 SysInfoLinux是用于计算Linux系统上的资源信息的插件 二、SysInfoLinux源码 package org.apache.hadoop.util;import java.io.
Hadoop-Yarn-NodeManager都做了什么
一、源码下载 下面是hadoop官方源码下载地址,我下载的是hadoop-3.2.4,那就一起来看下吧 Index of /dist/hadoop/core 二、上下文 在我的<Hadoop-Yarn-启动篇>博客中已经简要的分析了NodeManager的启动过程,NodeManager是管理整个集群资源的直接角色,因此我们有必要细致的分析下NodeManager都做了什么,一般Hado
NodeManager REST API’s
NodeManager REST API’s OverviewEnabling CORS supportNodeManager Information APIApplications APIApplication APIContainers APIContainer API Overview The NodeManager REST API’s allow the user to get s

java.io.IOException: Connection reset by peer;关闭hadoop集群时发现 dataNode 和 NodeManager 没关掉
关闭hadoop集群时 无意中使用 jps 发现 dataNode 和 NodeManager 没关掉 1.检查日志发现报错 仔细看了一下关闭情况发现 多了个localhost 于是打开/etc/hadoop/slaves 这个配置文件 vi ../etc/hadoop/slaves 发现果然多了一个localhost 才想起以前配置的时候没有删除 把localhost删除后保存退出

hadoop集群的NodeManager存在, 但在yarn上显示Unhealthy Nodes
也可以使用命令查看节点状态: [mmtrix@www hadoop-2.6.0-cdh5.4.1]$ bin/yarn node -list -all 查看yarn的log发现 2020-06-08 10:31:12,900 WARN org.apache.hadoop.yarn.server.nodemanager.DirectoryCollection: Dir
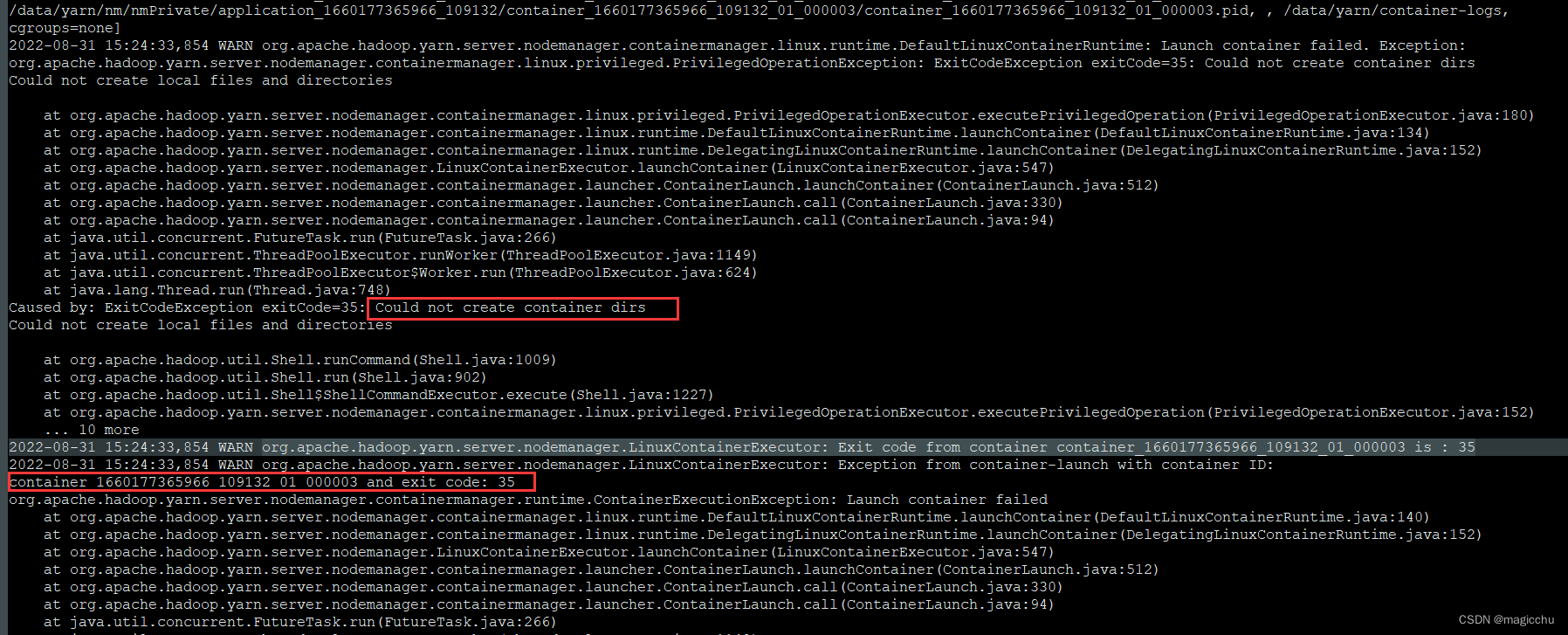
Nodemanager Unhealthy(exit code :143/35)
现象 CDH6.2.1版本,生产环境,通过cm页面发现yarn告警,提示Nodemanager Health Checker Bad,检查yarn前端8088页面,集群可用内存和CPU也相应减少,说明此NM失联不可用,重启NM后恢复正常。并且一个周内同一个数据NM节点出现两次这种情况。 问题定位 首先查找CM agent对NM的监控日志,进入目录: /var/run/cloudera-scm

记一次生产环境cdh6.3.2集群yarn组件nodemanager节点down掉的事故分析
有关2023.10.2日发现的yarn部分nodeManager组件节点不可用的原因分析 yarn组件异常情况始于2023.09.30日06时00分,恢复于2023.10.02日10点35分。每日凌晨6点,大数据定时任务:task1启动,该任务持续时长1小时20~25分钟左右,是mapreduce引擎类型任务,会使用大量cpu资源。赶上国庆节假日出行,遇到数据处理波峰,从大行程统计看,大行程从1
![weblogic NodeManager的 [Security:090482]BAD_CERTIFICATE alert 错误](https://img-blog.csdn.net/20130912162356578?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvemhvdWxlaWJsb2c=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
weblogic NodeManager的 [Security:090482]BAD_CERTIFICATE alert 错误
之前由于虚拟机换了ip,所以出现了如下错误: <Sep 12, 2013 4:17:12 AM BRT> <Warning> <Security> <BEA-090482> <BAD_CERTIFICATE alert was received from 192.168.1.127 - 192.168.1.127. Check the peer to determine why it rej