musetalk专题
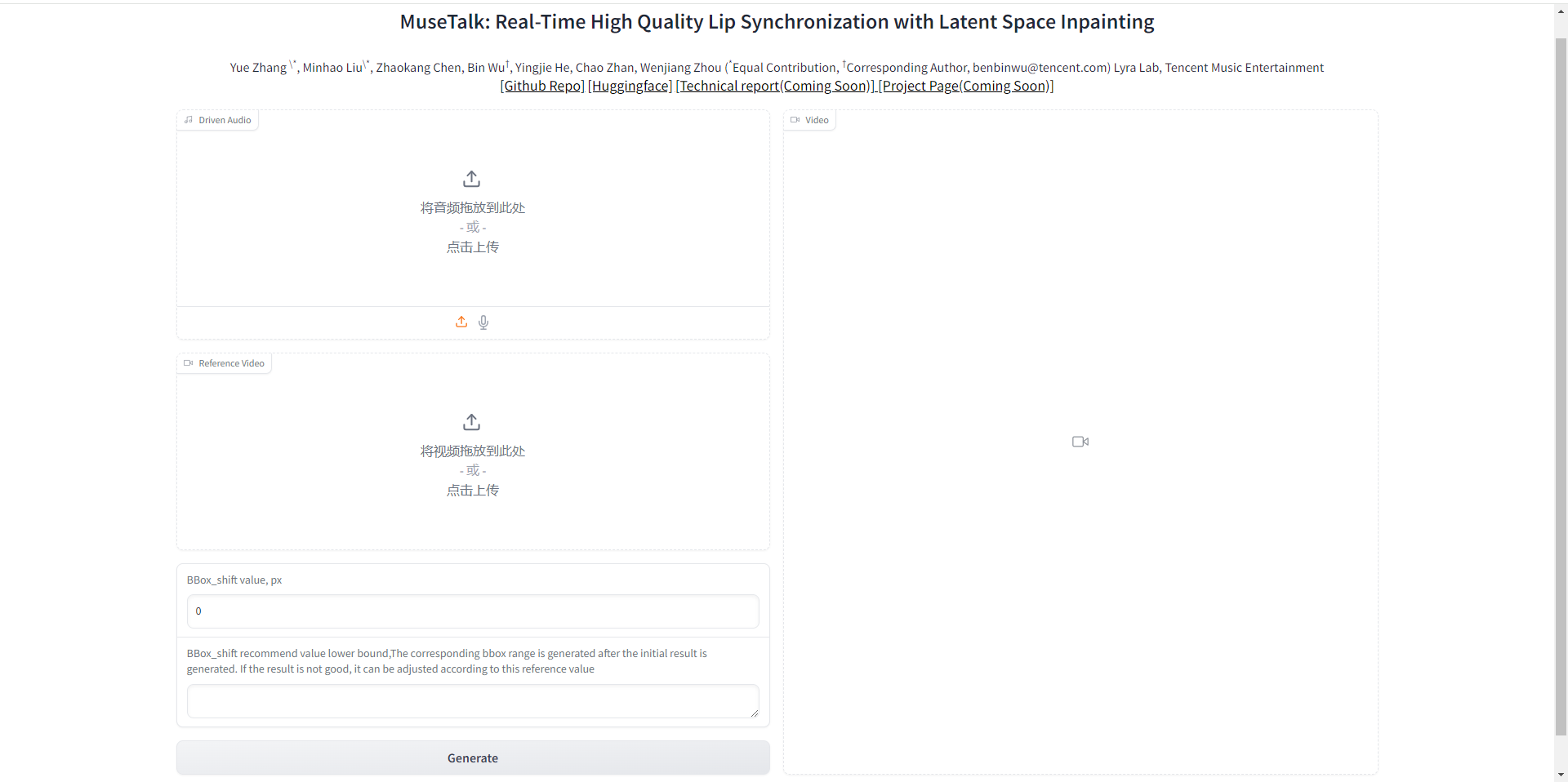
MuseTalk模型构建指南
一、介绍 MuseTalk 是由腾讯团队开发的先进技术,它是一个实时的音频驱动唇部同步模型。该模型能够根据输入的音频信号,自动调整数字人物的面部图像,使其唇形与音频内容高度同步。 二、特点 多语言支持:该模型支持多种语言,包括中文、英文和日文,能够服务于不同语言的用户群体。逼真的同步效果 :MuseTalk 生成的唇部动作与音频内容高度同步。出色的生成能力 :MuseTalk 在口型生成方

在线教程 | 青岛小哥焦恩俊魂穿黑神话悟空?MuseV + MuseTalk打造高质量数字人
使用传统的数字人训练方案生成一个高质量的数字人,常常需要大量的时间和算力资源,同时对训练素材的要求也较高,如果想要达到良好的唇形一致效果,通常需要数小时乃至更久。 MuseV 和 MuseTalk 的出现为数字人领域带来了新的突破,使用 MuseV 生成数字人视频后,再使用 MuseTalk 实现唇形和音频的同步,短短几分钟内即可实现完整的数字人制作。 「MuseV 不限时长的虚拟人视频生成