multivariate专题

scipy.stats.multivariate_normal.pdf出错得到的值都为0
stats.multivariate_normal.pdf出错得到的值都为0 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.0. 0. 0. 0. 0. 0.

Multivariate Linear Regression
clear,clc%梯度下降法x = load('ex3x.dat');y = load('ex3y.dat');m = length(y);x = [ones(m,1),x];%归一化数据feature scalingsigma = std(x); %求标准差mu = mean(x); %求均值x(:,2) = (x(:,2) - mu(2))./ sigma(2); x

论文笔记 -- A Transformer-based Framework for Multivariate Time Series Representation Learning
文章目录 A Transformer-based Framework for Multivariate Time Series Representation LearningRelated work(相关工作)Motivation(问题背景)Contribution(贡献)Model(模型)Unsupervised (self-supervised) pre-training(无监督和自监督

random.multivariate_normal和norm.rvs
np.random.multivariate_normal方法用于根据实际情况生成一个多元正态分布矩阵,其在Python3中的定义如下: def multivariate_normal(mean, cov, size=None, check_valid=None, tol=None) 其中mean和cov为必要的传参而size,check_valid以及tol为可选参数。 mean

多元排列熵 Multivariate Permutation Entropy
熵(Entropy) 信息论中熵的概念首次被香农提出,目的是寻找一种高效/无损地编码信息的方法:以编码后数据的平均长度来衡量高效性,平均长度越小越高效;同时还需满足“无损”的条件,即编码后不能有原始信息的丢失。这样,香农提出了熵的定义:无损编码事件信息的最小平均编码长度。 香农信息熵 Shannon entropy 香农信息熵是由香农提出的一个概念,它描述了信息源各可能事件发生的不确定性。这
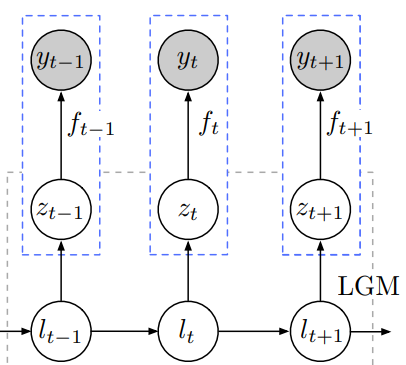
Normalizing Kalman Filters for Multivariate Time Series Analysis
l l l means latent state,LGM means ‘linear Gaussian state space models’ 辅助信息 作者未提供代码

【论文笔记】Multivariate Encoding Analysis of Medial Prefrontal Cortex Cortical Activity during Task Learn
【论文笔记】Multivariate Encoding Analysis of Medial Prefrontal Cortex Cortical Activity during Task Learning Abstract 研究表明,内侧前额叶皮层(mPFC)负责结果评估。研究表明,mPFC在执行任务时可能在目标规划和行动执行中发挥重要作用。 如果mPFC中编码的信息能够被准确地提取和识别