multibyte专题

python中使用FormatDataLibsvm转为txt文件后报错illegal multibyte sequence
‘gbk’ codec can’t decode byte 0xff in position 0: illegal multibyte sequence 这个报错是因为编码不对,正确的编码是ANSI编码,txt文件打开后另存为可以看到当前的文本文档编码 但是excel不能直接保存ANSI编码的txt文件 所以不能直接保存为ANSI编码 有两种解决办法 1.新建一个txt文件(新建的txt文件

UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence
pycharm报错UnicodeDecodeError: 'gbk' codec can't decode byte 0x8a in position 2: illegal multibyte sequence 解决办法: 然后: 就好了!
![【转】UnicodeEncodeError: 'gbk' codec can't encode character ...[省略] illegal multibyte sequence](https://pic.xiahunao.cn/getimgs/?img=https://images2017.cnblogs.com/blog/1135090/201711/1135090-20171114231439937-1206966913.png)
【转】UnicodeEncodeError: 'gbk' codec can't encode character ...[省略] illegal multibyte sequence
转载自:天宇之游 - 博客园:https://www.cnblogs.com/cwp-bg/p/7835434.html 【推荐】最后一种方法。 一、 最近使用python写入文件时,出现了如下的错误: 但是content的内容是unicode编码,不知道怎么和gbk扯上了关系,对content使用encode()和decode(),用gbk,utf-8,gb2312各种编码解码都

文章读取 'gbk' codec can't decode byte 0x9d in position 1793: illegal multibyte sequence
python读取文件的时候经常会遇到编码于解码的问题,其中常见的一种解码错误是'gbk' codec can't decode byte 0x9d in position 1793: illegal multibyte sequence 解决方法一:open('文件路径',encoding='utf-8').read() 解决方法二:open('文件路径',encoding='gb18
UnicodeDecodeError: 'gbk' codec can't decode byte 0xac in position 20: illegal multibyte sequence
代码如下: f = open("哈哈哈.txt", "r")t = f.read()f.close() 改正方法: f = open("哈哈哈.txt", "r",encoding="utf-8") #添加encoding参数 t = f.read()f.close() 类似的其他问题的总结:https://blog.csdn.net/sun9979/article/detai

UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xa6 in position 1536: illegal multibyte sequence
解决办法:检查项目中的 configs(配置) 中的.yml文件中是否 有中文字符,包括注释中也不能有中 文字符。若有的话,将中文字符删除即可。

ERROR:root:‘gbk‘ codec can‘t decode byte 0xba in position 890: illegal multibyte sequence
ERROR:root:'gbk' codec can't decode byte 0xba in position 890: illegal multibyte sequence 我红色特殊标出来的地方,可能因为代码环境等数字不一致,但问题性质和本质原因一样。都是因为在读取文件时出现编解码转换错误问题,原因就是编码不一致造成的。 解决办法: 如果是用的py3的版本,在你的编辑器中修改要读取的
codec can‘t encode character ‘\\xa0‘ in position 123: illegal multibyte sequence
出现这种一般是编码问题导致的,首先我将写入文件的编码方式更改为utf-8,问题解决了,不过写入文件之后,有变成了乱码。经过查找资料将编码方式更改为**gb18030**问题解决。

UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xa7 in position 213: illegal multibyte sequence
在查看Python项目已来报的时候,输入 pipreqs ./ 之后报如下错误: Traceback (most recent call last):File "d:\python37\lib\runpy.py", line 193, in _run_module_as_main"__main__", mod_spec)File "d:\python37\lib\runpy.py", line
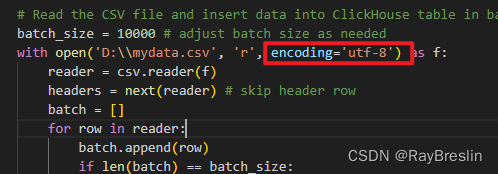
python报错:‘UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0xfe in position 683: illegal multibyte
一、问题描述 python读取csv文件,结果报错:‘UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xfe in position 683: illegal multibyte sequence’。 with open('my_data.csv', 'r') as f:reader = csv.reader(f)headers = nex

UnicodeDecodeError: 'gbk' codec can't decode byte 0x93 in position 130: illegal multibyte sequence
参考文献 https://blog.csdn.net/xxzhangx/article/details/74065578 报错中提示了”gbk”编码问题,那么我们的编码会在哪些地方出问题呢? 1、编码设置 第一行没有设置 # _*_ coding:utf-8 _*_ 2、后面处理数据时没有转码下,如open函数上 处理如下 with open("data.txt",