models3专题

Transformer and Pretrain Language Models3-6
Pretrain Language Models预训练语言模型 content: language modeling(语言模型知识) pre-trained langue models(PLMs)(预训练的模型整体的一个分类) fine-tuning approaches GPT and BERT(现在主流的基于fine-tuning的语言模型) PLMs after BERT(BE
Transformer and Pretrain Language Models3-4
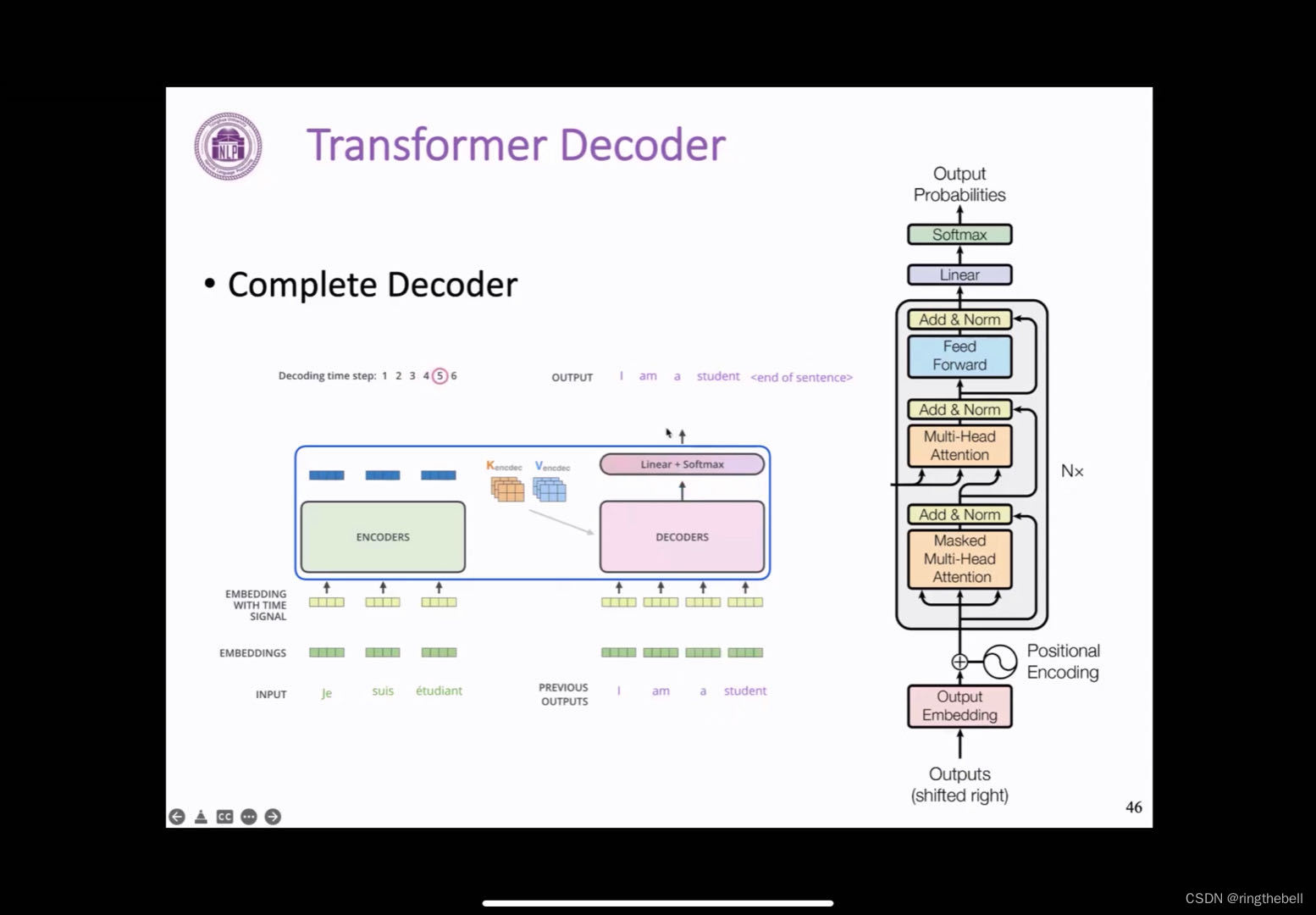
Transformer structure 模型结构 Transformer概述 首先回顾一下之前的RNN的一个端到端的模型,以下是一个典型的两层的LSTM模型,我们可以发现,这样一个RNN模型,一个非常重要的一个缺点就在于,它必须顺序地执行,对于文本这样一个序列,它必须先计算得到第一个位置的一个表示,然后才可以往后计算文本第二个的一个表示,然后接着才能去计算第三个。 而这样的模式,其实对于

Transformer and Pretrain Language Models3-5
Transformer结构(优化Tricks) Transformer在训练和生成过程中,采用了很多小技巧: 首先是训练过程,训练过程中采用了一种叫checkpoint average技术,以及ADAM的一个优化器来进行参数更新,另外的话,为例提高模型的训练效果,防止过拟合,会在残差连接之前加上dropout。 在输出层,也加入了label smoothing的方式来提高训练效率,然后最后在