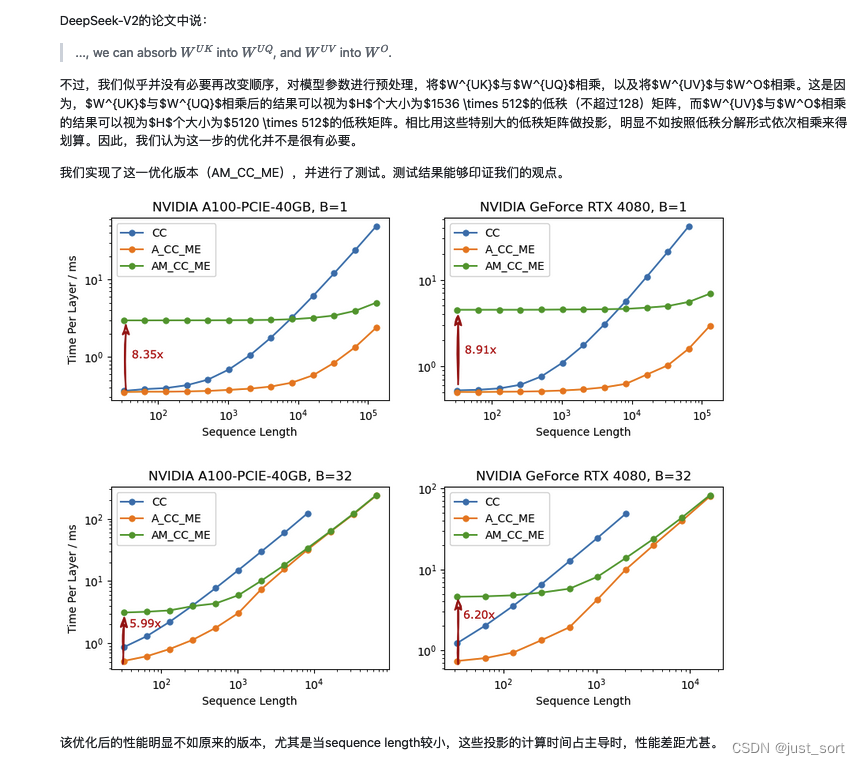
mla专题
一文通透DeepSeek-V2(改造Transformer的中文模型):从DeepSeek LLM到DeepSeek-V2的MLA与MoE
前言 成就本文有以下三个因素 24年5.17日,我在我司一课程「大模型与多模态论文100篇」里问道:大家希望我们还讲哪些论文 一学员朋友小栗说:幻方发布的deepseek-v224年5.24日,我司一课程「大模型项目开发线上营1」里的一学员朋友问我:校长最近开始搞deepseek了吗?刚看了论文,没搞懂MLA那块的cache是怎么算的,我总觉得他的效果应该类似MQA才对,但是反馈是挺好的 我当
大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
首先,本文回顾了MHA的计算方式以及KV Cache的原理,然后深入到了DeepSeek V2的MLA的原理介绍,同时对MLA节省的KV Cache比例做了详细的计算解读。接着,带着对原理的理解理清了HuggingFace MLA的全部实现,每行代码都去对应了完整公式中的具体行并且对每个操作前后的Tensor Shape变化也进行了解析。我们可以看到目前的官方实现在存储KV Cache的时候并不

GQA,MLA之外的另一种KV Cache压缩方式:动态内存压缩(DMC)
0x0. 前言 在openreview上看到最近NV的一个KV Cache压缩工作:https://openreview.net/pdf?id=tDRYrAkOB7 ,感觉思路还是有一些意思的,所以这里就分享一下。 简单来说就是paper提出通过一种特殊的方式continue train一下原始的大模型,可以把模型在generate过程中的KV Cache分成多个段,并且每个token都会学出

MLA Review之五:回归
回到回归的正题,回归问题是机器学习领域中应用的比较广的一种方法,不过我觉得大部分的回归模型都是广义线性模型,在Andrew NG的课程中,对广义线性模型做了比较详细的推导,这篇文章的内容是,线性回归、局部加权回归、岭回归以及前向逐步回归,除了前向逐步回归之外,其他的都是广义线性回归模型,基本思路都是 1,确定损失函数 2,使用梯度下降(或者梯度上升)求解权重参数,算是套路,而这两种套路使用Pyt

MLA Review之四:logistic回归
终于来到logistic回归,logistic回归其实很简单,之前的说到的神经网络就用到了这个方法,其中最重要的就是使用了sigmoid损失函数。当然使用的方法也就最简单的梯度下降法,这里并没有使用之前神经网络的随机梯度下降法,也是为了简单起见。因为之前在神经网络里面使用过了,所以这篇文章就略微介绍下。 logistic回归是属于广义线性回归的一种,基本形式: z=w0+w1*x

MLA Review之三:朴素贝叶斯分类
朴素贝叶斯(Naive Bayes),贝叶斯概率论在整个统计学习上都是泰山北斗一样的存在,《Pattern Recognization and Machine Learning》这一扛鼎之作全书的思想其实就是贝叶斯概率论,简单的说就是先验代替后验。 我们先来给朴素贝叶斯找一点理论支持 贝叶斯概率公式:P(A|B)=P(A)*p(B|A)/P(B) ,而根据要求,我们需要做

MLA Review之二: 决策树
分类决策树是一种描述对实例进行分类的属性结构,决策树由内部节点和叶节点,内部节点表示一个特征或者属性,叶节点表示一个类。 Part 1 :决策树生成 用决策树分类其实是一个if-then的过程,根据一个特征值的取值将原始的数据进行分类,比如,银行往往会根据个人情况和信用进行处理是否借贷,其评比条件如下图: 那么可能其中的一个决策树就会如下: 分类树也就是这样。