mappartitions专题

SparkRDD之mapPartitions和mapPartitionsWithIndex
1.mapPartitions mapPartition可以这么理解,先对RDD进行partition,再把每个partition进行map函数。 下面的例子,将整数转为字符串: package com.cb.spark.sparkrdd;import java.util.ArrayList;import java.util.Arrays;import java.util.Iterato
Spark算子:RDD基本转换操作(5)–mapPartitions/mapPartitionsWithIndex
mapPartitions def mapPartitions[U](f: (Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U] 该函数和map函数类似,只不过映射函数的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代
spark中mapPartitions双重循环或两次遍历(duplicate)
在spark当中通常需要对mapPartitions内部进行计算,这样可以在不进行网络传输的情况下,对数据进行局部计算 而mapPartitions中的迭代器为Iterator scala中的Iterator只能进行一次迭代,使用过后就消失了,所以在mapPartitions中既不能两次遍历 如:一次mapPartitions求最大最小值 val it = Iterator(20, 4

Learning Spark——Spark连接Mysql、mapPartitions高效连接HBase
执行Spark任务免不了从多个数据源拿数据,除了从HDFS获取数据以外,我们还经常从Mysql和HBase中拿数据,今天讲一下如何使用Spark查询Mysql和HBase 1. Spark查询Mysql 首先,Spark连接Mysql当然需要有Mysql的驱动包,你可以在启动时加上如下命令: bin/spark-shell --driver-class-path /home/hadoop/j
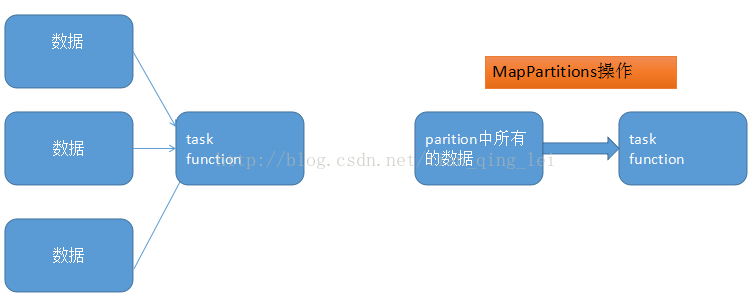
Spark---算子调优之MapPartitions提升Map类操作性能
spark中,最基本的原则,就是每个task处理一个RDD的partition。 1、MapPartitions操作的优点: 如果是普通的map,比如一个partition中有1万条数据;ok,那么你的function要执行和计算1万次。 但是,使用MapPartitions操作之后,一个task仅仅会执行一次function,function一次接收所有的partition数据。只要
利用repartition和mapPartitions替代reduce功能
数据:用户,时间,地点 样例: 10001,20190401 14:20:06,2000000001000001000000000004879310002,20190612 00:36:24,0000000100000005000000000018136210002,20190612 01:49:05,00000001000000050000000000181362 需求统计:用户在每个地
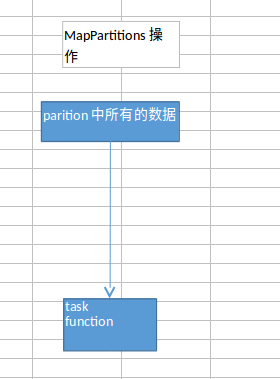
69.Spark大型电商项目-用户访问session分析-算子调优之MapPartitions提升Map类操作性能
目录 普通的map操作 MapPartitions操作 MapPartitions操作的优点 MapPartitions操作的缺点 MapPartitions系列操作建议 本篇文章记录用户访问session分析-算子调优之MapPartitions提升Map类操作性能。 普通的map操作 数据一条一条的操作。 public static JavaPairRDD

Spark中mapPartitions算子详解介绍
文章目录 一、Spark中mapPartitions算子详细介绍1、函数介绍语法:功能: 2、代码示例例1例2 3、注意事项 一、Spark中mapPartitions算子详细介绍 上一节我们讲到如何使用map算子对RDD中的数据进行映射处理,但是map函数有个缺点就是不能够批处理,他是每次只处理一个元素,而本节使用的 mapPartitions 进行的类似于批处理,每次