magvit专题
![[WIP]Sora相关工作汇总VQGAN、MAGVIT、VideoPoet](https://img-blog.csdnimg.cn/direct/22aa1d0fcceb4c4081e72bd8d52d6907.png)
[WIP]Sora相关工作汇总VQGAN、MAGVIT、VideoPoet
视觉任务相对语言任务种类较多(detection, grounding, etc.)、粒度不同 (object-level, patch-level, pixel-level, etc.),且部分任务差异较大,利用Tokenizer核心则为如何把其他模态映射到language space,并能让语言模型更好理解不同的视觉任务,更好适配LM建模方式,目前SOTA工作MAGVIT-v2,VideoPo
MAGVIT: Masked Generative Video Transformer
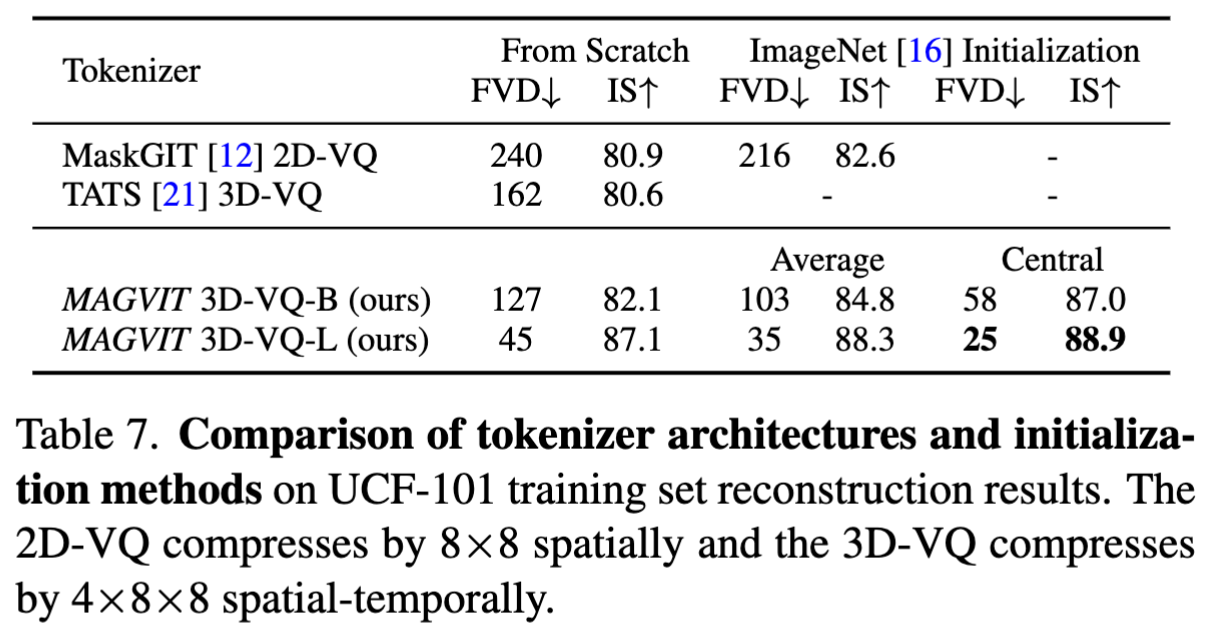
Paper name MAGVIT: Masked Generative Video Transformer Paper Reading Note Paper URL: https://arxiv.org/abs/2212.05199 Project URL: https://magvit.cs.cmu.edu/ Code URL: https://github.com/google-r
MAGVIT: Masked Generative Video Transformer
Paper name MAGVIT: Masked Generative Video Transformer Paper Reading Note Paper URL: https://arxiv.org/abs/2212.05199 Project URL: https://magvit.cs.cmu.edu/ Code URL: https://github.com/google-r