magicpose专题
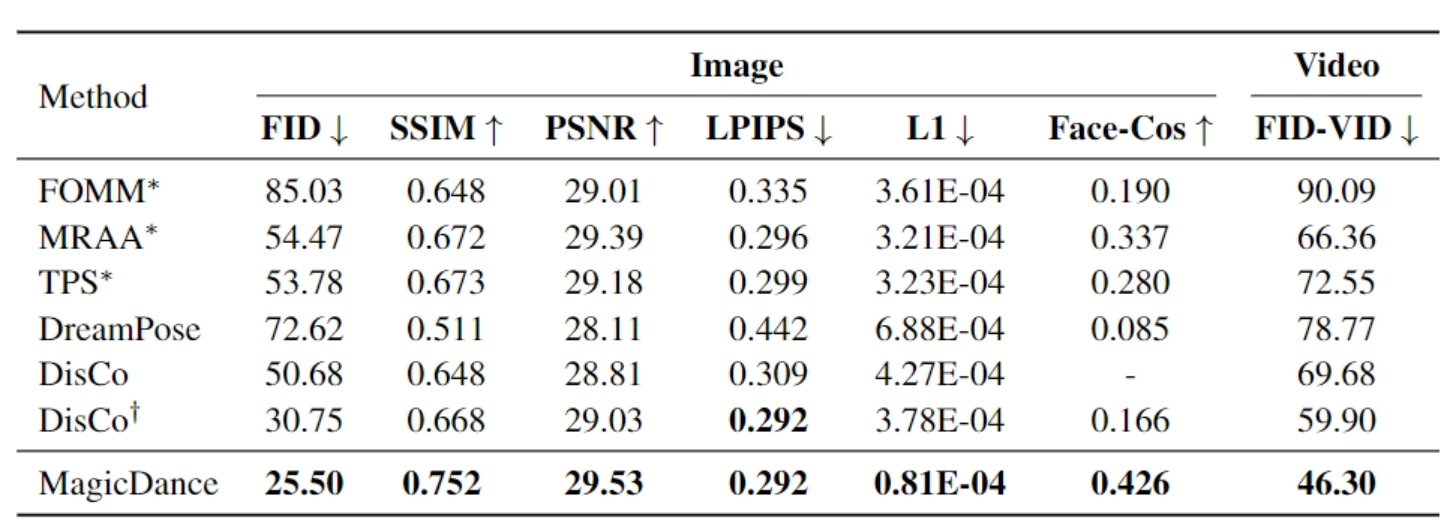
南加州大学字节提出MagicPose,提供逼真的人类视频生成,实现生动的运动和面部表情传输,以及不需要任何微调的一致的野外零镜头生成。
MagicPose可以精确地生成外观一致的结果,而原始的文本到图像模型(如Stable Diffusion和ControlNet)很难准确地保持主体身份信息。 此外,MagicPose模块可以被视为原始文本到图像模型的扩展/插件,而无需修改其预训练的权重。 相关链接 论文链接:https://arxiv.org/pdf/2311.12052.pdf 项目链接:https://githu