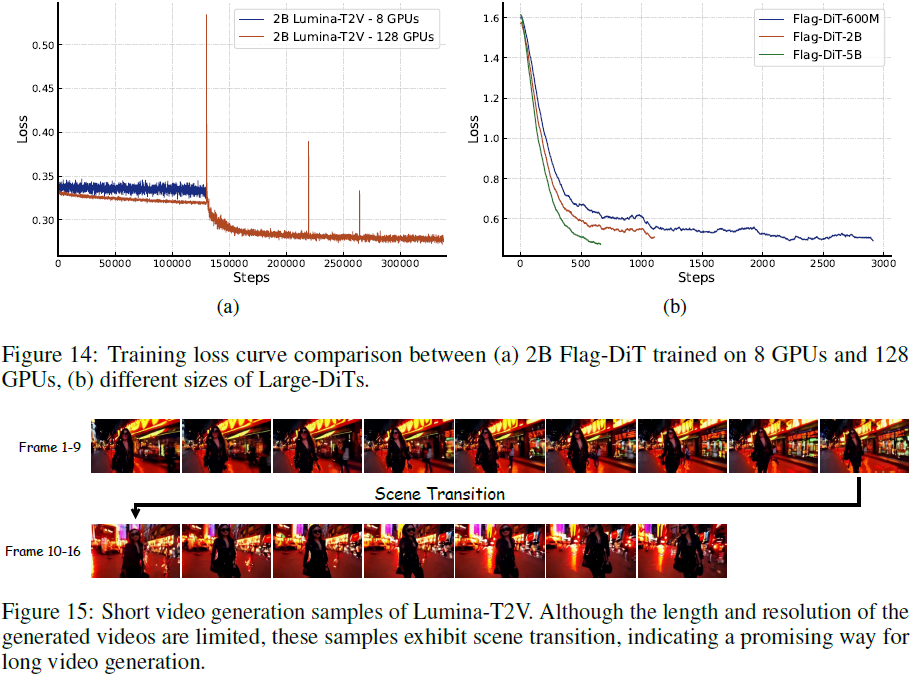
lumina专题
(2024,Flag-DiT,文本引导的多模态生成,SR,统一的标记化,RoPE、RMSNorm 和流匹配)Lumina-T2X
Lumina-T2X: Transforming Text into Any Modality, Resolution, and Duration via Flow-based Large Diffusion Transformers 公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群) 目录 0. 摘要 2. 方法 2.1 重新审视

介绍一下Lumina-T2X在哪些领域有应用
接上文【文末附gpt升级方案】Lumina-T2X:大型扩散DiTs在多模态内容生成中的新篇章-CSDN博客 Lumina-T2X是一个创新的多模态内容生成模型,其应用领域广泛,特别是在需要生成多种类型媒体内容的应用场景中表现突出。以下是Lumina-T2X在主要领域的应用概述: 图像生成: Lumina-T2X的系列模型之一,Lumina-T2I,展示了出色的图像生成质量。该模型可以生成任意

Lumina-T2X 一个使用 DiT 架构的内容生成模型,可通过文本生成图像、视频、多视角 3D 对象和音频剪辑。
Lumina-T2X 是一个新的内容生成系列模型,统一使用 DiT 架构。通过文本生成图像、视频、多视角 3D 对象和音频剪辑。 可以在大幅提高生成质量的前提下大幅减少训练成本,而且同一个架构支持不同的内容生成。图像质量相当不错。 由 50 亿参数的 Flag-DiT 驱动的 Lumina-T2I,其训练计算成本仅为同类 6 亿参数模型的 35%。 目前放出了 Lumina-T2I 图像生成